以语言预训练模型为基础的Agent目前是研究热点,应用前景广阔。然而,一个突出问题在于,由于受制于LLM的模态特性,它仅能处理语言形式的输入数据。
有趣的是,人类借助视觉与图形用户界面进行交互。
在图形用户界面(GUI)场景中,视觉交互比其他形式更直观、本质,能够高效且全面地传递环境信息。此外,许多GUI界面缺乏源码,也难以用语言准确描述。如果能将大型模型改造为视觉智能体,直接以图像形式输入GUI界面,让模型通过视觉进行理解、规划与决策,这将是一种更加直接高效的方法,并具有巨大的优化潜力。
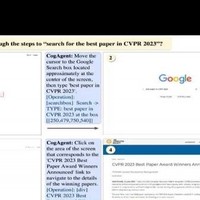
我们提出了多模态大模型CogAgent,支持视觉驱动的GUI Agent。所示,展示了其工作流程与功能。
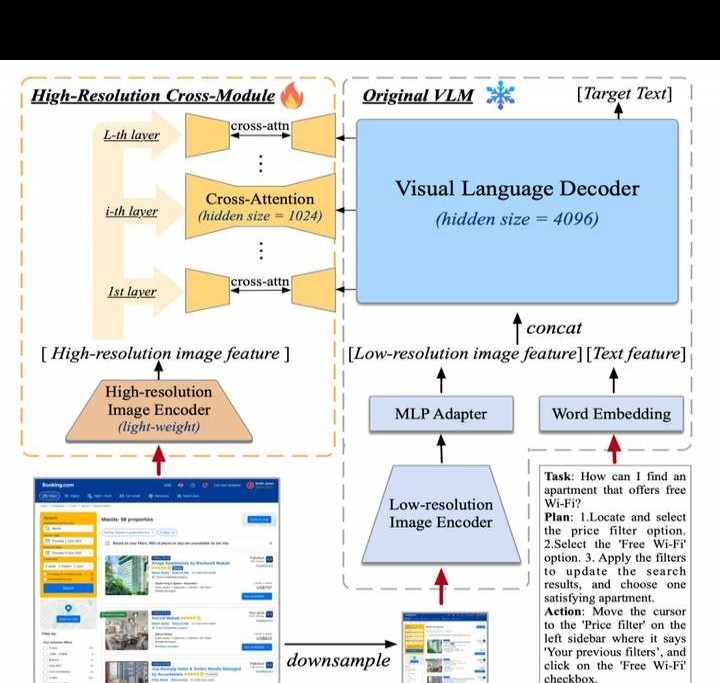
为提升模型对高分辨率图像的理解能力,使其能清晰识别约720p的GUI屏幕输入,我们将图像输入分辨率提高到1120×1120,远超以往模型常用的500×500以下水平。
然而,分辨率提高会使图像序列快速增加,造成计算和显存开销过大,这正是当前多模态预训练模型普遍采用低分辨率图像输入的原因之一。
我们设计了一种轻量化的高分辨率交叉注意力模块,在原有的低分辨率大图像编码器(4.4亿参数)基础上,新增了一个高分辨率的小图像编码器(0.3亿参数),并通过交叉注意力机制与原有视觉语言模型进行交互。同时,在交叉注意力中采用较小的隐藏层维度,进一步减少显存占用和计算成本,提升效率。
实验结果显示,此方法能让模型有效处理高分辨率图片,同时显著减少显存和计算成本。
消融实验中,我们对比了该结构与CogVLM原始方法的计算量。实验结果显示,随着分辨率提高,采用文中提出的方法(with cross-module,橙色)只会带来极少的额外计算量,且其增长与图像序列长度呈线性关系。
尤其值得注意的是,CogAgent在1120×1120分辨率下的计算开销(FLOPs),甚至低于CogVLM在490×490分辨率时的一半。在INT4单卡推理测试中,CogAgent模型于1120×1120分辨率下占用约12.6GB显存,相比CogVLM在224×224分辨率时的显存使用量,仅增加了不到2GB。
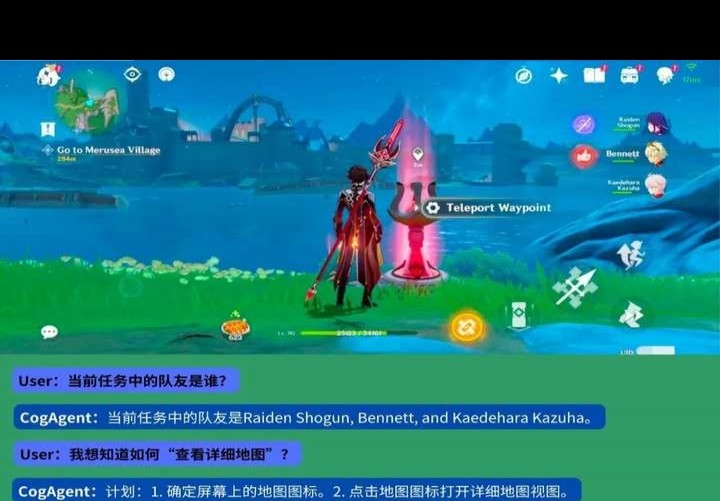
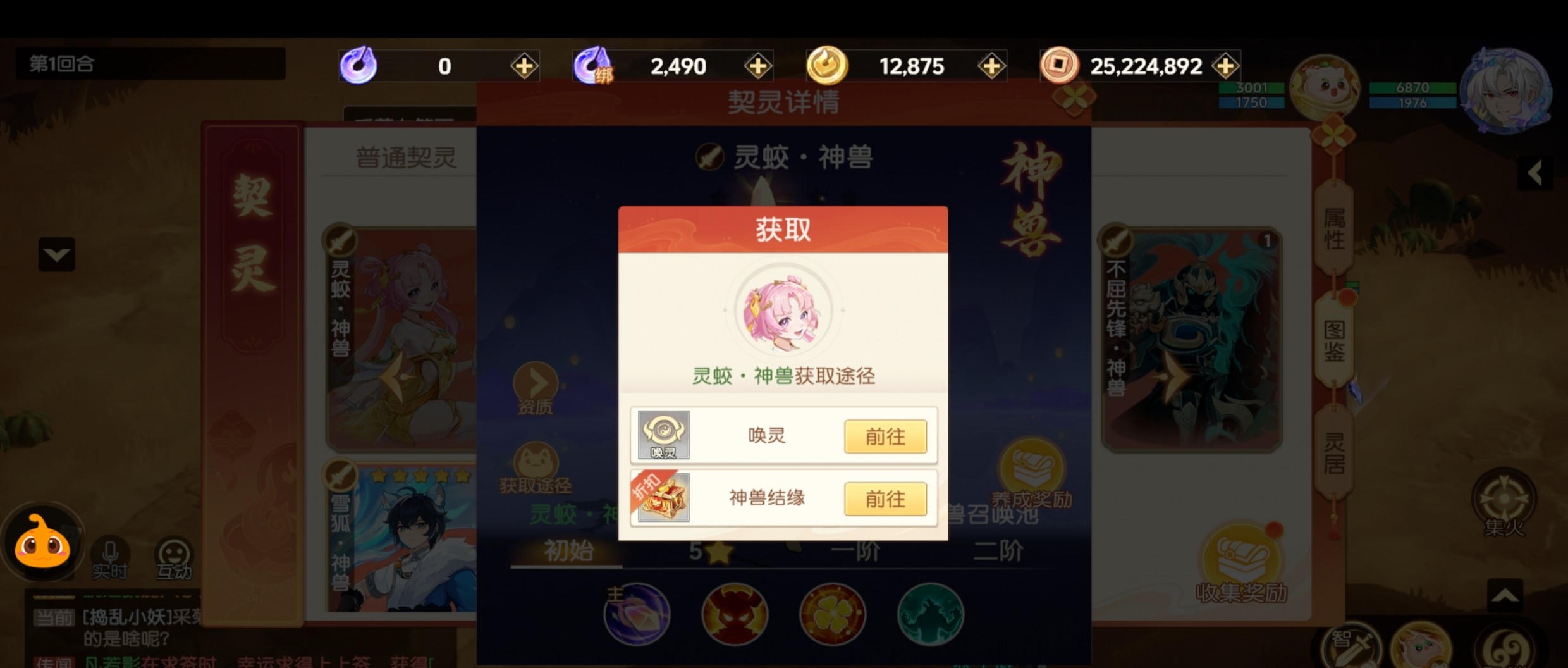
接下来,我们展示一个原神场景的例子。