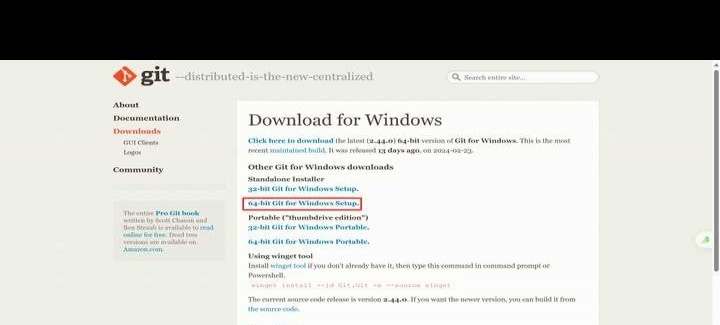
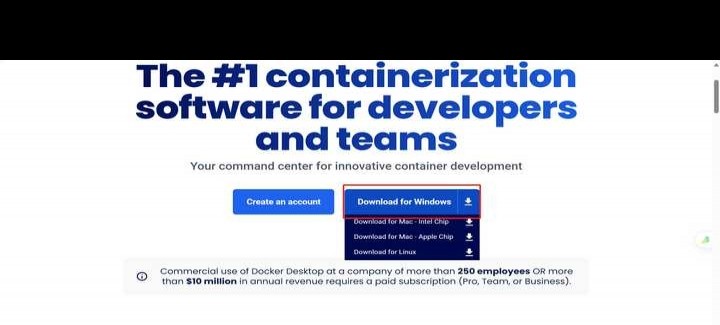
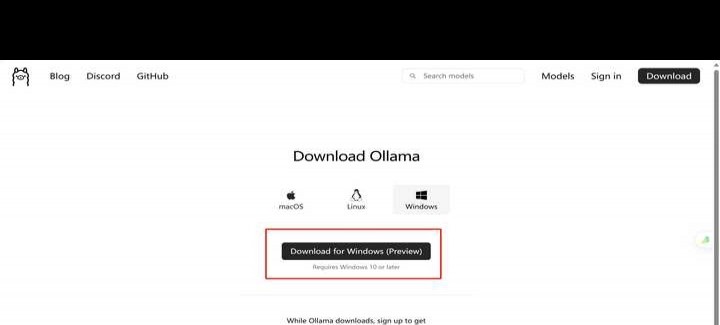
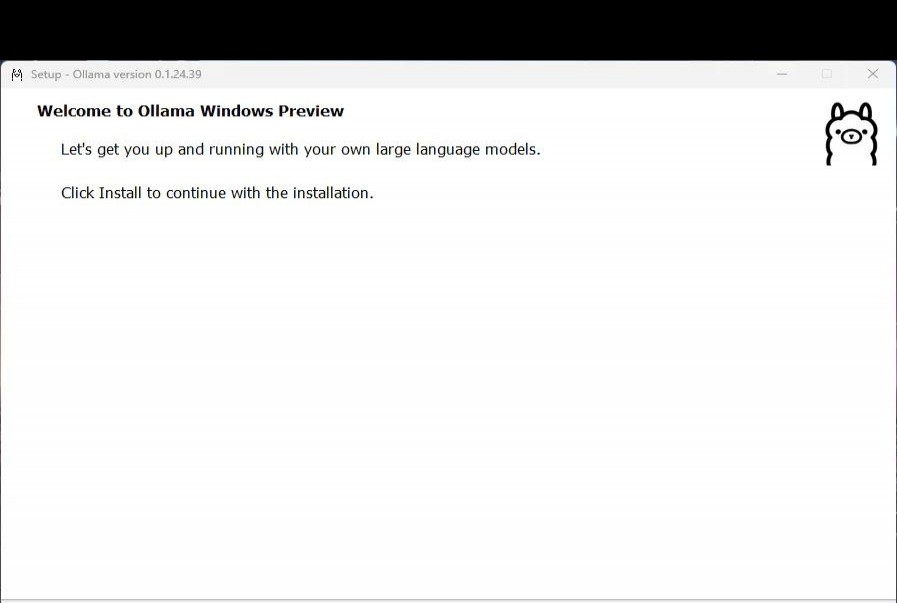
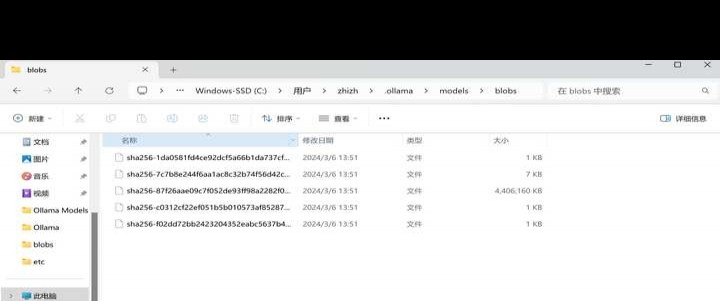
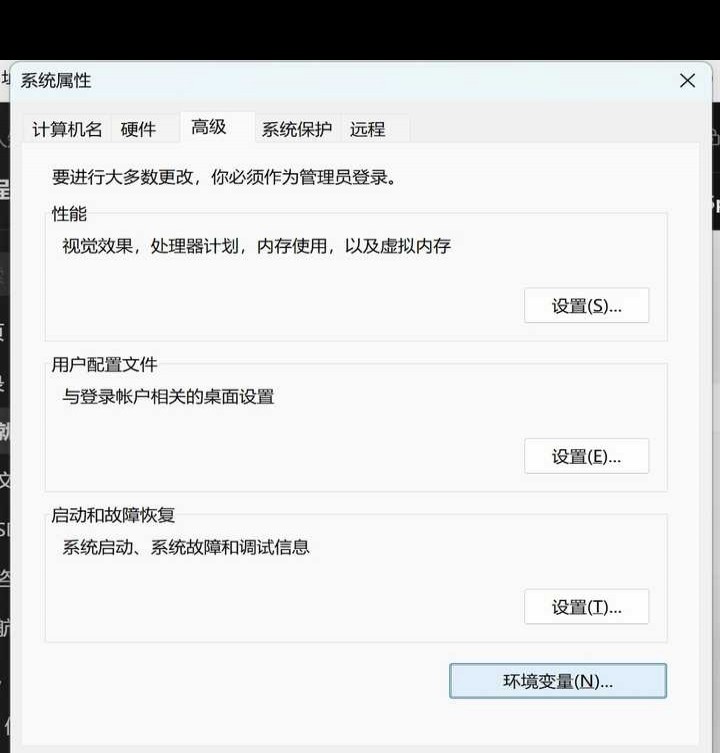
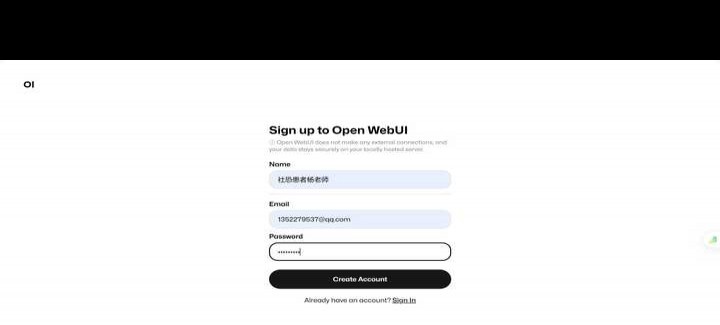
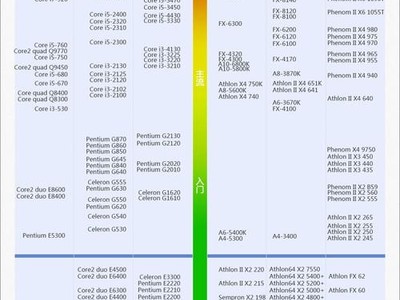
1.6万 浏览 311 回答
2.1万 浏览 194 回答
1.3万 浏览 181 回答
1273 浏览 119 回答
15.4万 浏览 73 回答
评论 56
评论 23
评论 68
评论 57
评论 67
8068 浏览 5 回答
9866 浏览 1 回答
21.6万 浏览 5 回答
8250 浏览 5 回答
5983 浏览 6 回答
1.4万 浏览 5 回答
4823 浏览 7 回答
9.3万 浏览 5 回答
7091 浏览 5 回答
1.2万 浏览 6 回答
6684 浏览 5 回答
644 浏览 6 回答
6646 浏览 6 回答
8657 浏览 7 回答
328 浏览 6 回答
经过核实后将会做出处理,感谢您为社区和谐做出贡献。
{{adWord}} {{factory}}
{{adWord}}