相关内容链接
GPU无法独立工作,它作为CPU的协处理器,需由CPU调度。CPU与GPU共同构成异构计算架构。其中,CPU擅长逻辑处理,但在大量数据运算方面能力有限;而GPU正好相反,能够高效并行处理海量数据运算任务。这种分工协作有效提升了计算效率。
此处添加图片说明文字
2、CUDA运行时应用程序接口

请上传图片,我会描述内容。
编写首个CUDA程序

请在此处添加图片说明文字。
使用nvcc编译cuda代码,命令如下:nvcc test1.cu -o test1,即可完成编译操作。

请在此处添加图片说明

请上传图片,我来描述内容。

此处添加图片说明文字。

请添加图片描述内容

此处添加图片说明文字

此处添加图片说明文字

请在此处添加图片说明

请在此处添加图片说明文字。

此处添加图片说明文字

此处添加图片说明文字。
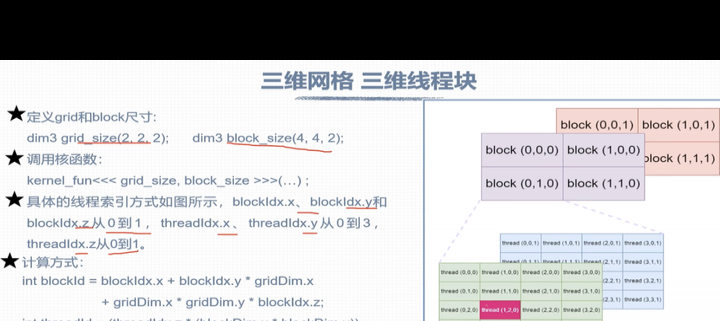
此处添加图片说明文字

请在此处添加图片说明

请在此处添加图片说明

请在此处添加图片说明文字。

请添加图片描述内容

此处添加图片说明文字

请在此处添加图片说明

此处添加图片说明文字

请在此处添加图片说明

请在此处添加图片说明

请在此处添加图片说明

请在此处添加图片说明

请在此处添加图片说明

请添加图片描述内容

请在此处添加图片说明

请添加图片描述内容

请在此处添加图片说明

请在此处添加图片说明

此处添加图片说明文字

请在此处添加图片说明
利用GPU完成矩阵运算任务
CUDA 运行时 API 通常会返回错误代码,其返回值类型为 cudaError_t。之前例子中提到,当 CUDA 运行时 API 执行成功时,返回的错误代码为 cudaSuccess,且运行时 API 返回的状态值是一个枚举变量。

请在此处添加图片说明文字。

请提供一下图片内容说明
检查错误调用函数:
获取CUDA程序最近一次错误信息的函数——cudaGetLastError。

请添加图片描述信息
在调用核心函数后,添加以下代码:
CUDA事件计时代码如下,只需将需计时的代码嵌入计时代码之间:
这段代码计算核函数运行10次的平均时间,虽然实际执行11次,但首次调用通常耗时较长,可能会导致测量结果不准确。为提高精度,忽略第一次调用的时间,仅取后10次的平均值作为最终结果。
CUDA 5.0起,nvprof作为命令行分析工具出现,它是一个可执行文件,用于性能分析。
执行命令如下,其中 exe_name 表示可执行文件名称:

此处添加图片说明文字。

此处添加图片说明文字

请上传图片,我来描述内容。
CUDA运行时API无法查询GPU的核心数。

此处添加图片说明文字
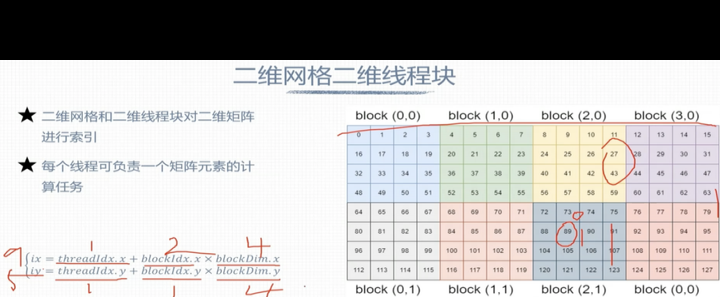
请上传图片,我来描述内容。

请上传图片,我会描述。

此处添加图片说明文字

此处添加图片说明文字。