先看人工智能系统的安全挑战,再看应对方案。
2016年10月,美国国家科学技术委员会和美国网络与信息技术研发小组委员会一同制定并发布了美国国家人工智能研究和发展战略计划。该计划指出,人工智能系统所面临的安全挑战主要集中在以下几个方面。
很多时候,人工智能系统会被应用于复杂且不确定的环境里。如此一来,就极有可能存在大量被遗漏、无法被彻底检查或测试的情况,而这些情况也许会给系统带来意想不到的冲击。并且,当前实际投入使用的人工智能系统大多为专用系统,像人脸识别系统就只能用于人脸识别,语音识别系统仅能进行语音识别,智能股票系统也只能分析交易市场中的交易等。一旦出现意外状况,这些系统通常无法凭借自身能力解决问题,必须依靠人工干预。所以,针对重要的系统,务必要做好应急预案与灾备工作等。
软件产品相当复杂,存在漏洞在所难免。我们所处的世界同样复杂,在软件开发与实验室测试时,很多意外状况难以被发觉。测试正常,一上线就出各种问题的现象十分常见,有软件开发经验的人应该深有感触。有些有趣的网络帖子还调侃说,有人会在软件系统上线前请和尚或道士做法事,祈求上线后别出问题。这种迷信做法不可取,但这也确实体现出程序员对软件上线后可能遭遇的怪异状况心里没底。
2018年10月29日,印尼狮航一架波音737 MAX 8客机起飞13分钟后失联,于印尼卡拉望地区附近坠毁,机上189人丧生。2019年3月10日,埃塞俄比亚航空一架同型号客机在飞往肯尼亚途中坠毁,机上149名乘客与8名机组人员全部遇难。事故发生后,据华盛顿邮报报道,有安全专家经调查指出,波音公司隐瞒了737 MAX系列机型的一个新自动控制系统,该系统有潜在俯冲撞机风险。飞行员、航空公司和管理机构事先都不知情,绝大多数人毫无应对准备,这或许就是航班坠毁的原因。
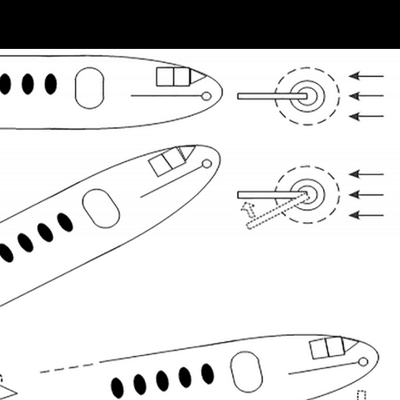
所谓新的自动控制系统,就是波音737 MAX 8所配备的自动防失速系统,也就是机动特性增强系统(MCAS)。从图1能够看到,飞机飞行的时候,机头抬得越高,攻角(气流和机翼弦线间的夹角)就越大。一旦攻角超出了特定范围,飞机就有失速的危险。波音737 MAX 8配备的自动防失速系统在判定飞机失速时,无需飞行员干预就能接管飞机的操控,并且让机头下压,从而改变失速状态。
美国联邦航空管理局称:迎角传感器若错误输出数据,水平稳定器可能下倾飞机机头,致使飞机难以操控。这意味着传感器故障传输错误数据时,自动控制系统会让飞机俯冲。并且,飞行员关闭自动驾驶系统自认为完全掌控飞机时,该系统仍每5秒自动执行俯冲操作。于是,飞行员拉起机头后,每隔5秒系统就使飞机俯冲。飞行员再拉起机头,5秒后系统又会按下机头让飞机俯冲。如此反复,在和机器的这种拉锯中,人必然失败,毕竟机器能不停重复动作,人却不能。
汽车自动驾驶系统还在研发,未大规模使用,而飞机自动驾驶系统已较成熟且被大规模应用。它能按预设航线全程驾驶飞机,甚至可完成降落。飞机驾驶环境复杂,由此可见,波音737 MAX 8迎角传感器故障这种情况未被认真考量和测试。
前面提到过,面对复杂环境与系统,我们很难预先考虑到所有状况,意外时有发生。所以,人工智能系统故障时得有应急预案,必要时要有能让系统停止运行并转为人工接管的方法。
此外,除系统运行中自然产生的意外状况外,还有些人为情况,也就是攻击者蓄意攻击的行为,这些行为也需被视为对人工智能系统安全的影响因素。
涌现性一般是说多个要素构成系统后,会产生在构成系统前单个要素所没有的性质。像细胞构成器官,器官组成人体,人体从细胞、器官中涌现出来,形成新的层级,还具备低层级要素所没有的多种性质。
我们以一个例子来理解涌现行为(Emergent Behavior)。人工智能运用机器学习方法,从数据学习过程中产生涌现现象。若不控制机器学习的数据,涌现出的人工智能可能并非我们所期望的。比如,部分人工智能系统部署后会持续学习,其行为主要取决于部署后的无监督学习阶段。在此种情况下,我们难以把控系统学习数据的合理性与有效性,也就很难预测系统的行为。
微软人工智能研发部门曾在推特开展对话理解实验,其工程师开发出名为Tay的在线聊天机器人。Tay于2016年3月23日上线,然而不到24小时就下线了。因为在如此短的时间内,Tay变成了十足的种族主义者和性别歧视者,这与网络言论有关。由于Tay学习的数据是未经甄别筛选的网络言论,所以它的行为被完全引向了我们不愿看到的方向。
把人类目标描述转化成计算机指令非常困难,所以对人工智能应用系统编程可能不符合设计预期目标,进而出现目标设定偏差(Goal Misspecification)。
人类的目标往往难以清晰描述,毕竟有时我们自己都不清楚想要什么。就像我们让自动驾驶汽车以最快速度抵达机场,结果它就会全速前行、闯红灯、超速。人工智能为达成被赋予的目标,可能会动用它知晓的所有手段,哪怕是人类眼中疯狂的方式,这并非我们所期望的。在此例中,要让命令合理,我们就得添加诸如遵守道路限速、不闯红灯之类的限制条件。
我们得谨慎地给人工智能设定目标。目标设定不当会带来极大麻烦,而且随着人工智能能力不断增强,不当目标可能造成的损失也会越发严重。比如,若给医疗机器人设定消灭癌症的目标,当它无法治愈患者时,为达成目标,就可能错误地杀死患者;要是要求人工智能保护人类,当它觉得人类过于脆弱无法自我保护时,也许就会将人类软禁起来。这些情节在科幻小说和影视作品中屡见不鲜。虽然目前这只是虚构的,但其中反映的问题是真实的,即人工智能可能会以我们意想不到的不合理方式去实现我们为其设定的目标。
人机交互这个概念我们都比较熟悉。很多时候,人工智能系统的行为会被人类与之的交互极大影响。在这样的情形下,人类与人工智能系统交互时的不同反应,或许会对系统的安全性产生影响。
当下,许多人工智能系统在设计上未被给予完全的自主性,其行为会受人类指示左右,这既正常又必要,毕竟现阶段人工智能系统还无法完全自主应对所有意外状况。就拿自动驾驶来说,很多自动驾驶技术都规定在突发状况出现时,需要人类驾驶员介入处理,所以人类驾驶员和自动驾驶系统的交互必然会影响到自动驾驶系统的安全性。在此情形下,自动驾驶系统与人类驾驶员交互界面的易用性,以及人类驾驶员对交互界面的熟悉程度,都有较高要求。
人工智能系统面临安全挑战,我们要从以下方面提升其安全性与可靠性。
人工智能的可解释性(即透明度)的提升是一项关键研究挑战。
多种人工智能方法(深度学习也包含在内)对用户而言缺乏透明度,能解释其结果的现有机制寥寥无几。运用深度学习解决问题时,神经网络里众多参数、权重的意义往往难以解释。不少科学家将深度学习方法称作炼金术。在某些层面,当下的深度学习确实与炼金术有相似之处,调整一些配料(像网络模型参数、数据等)就能神奇地把问题解决,但我们却很难说清其中缘由。
这种现象是潜在的危险因素,会给某些领域(如医疗保健)带来问题。在医疗领域应用人工智能时,医生需合理的解释来验证诊断或治疗过程是否正确,可当前人工智能技术的解释技术往往不够精准。虽然现在人工智能已能识别多种医疗影像,像识别病灶,且识别结果准确率较高,甚至超过普通医生,但在解释识别结果方面却困难重重。
所以,人工智能研究者得开发出透明系统,从根本上向用户解释结果产生的缘由。
人工智能在当下是人类的一个工具。人类的工具从古至今发展得极为复杂,从石器、木棒的远古时期,到金属器具、机械的出现,再到轮船、汽车、飞机、电子仪器、计算机,直至人工智能。简单工具容易被信任,使用者一眼就能明白用途,像木棒的打击功能,使用者很容易信赖且知晓原理。但复杂工具要获取信任较难,就像有些人不信任飞机,甚至不敢乘坐。
人工智能系统若要赢得使用者的信任,就得既准确可靠,又能提供信息量大且用户友好的界面。使用者也需要花时间充分学习和接受培训,从而掌握系统的操作方式与性能局限。从那些已被使用者广泛信任的复杂系统(如车辆手动控制系统)的特性来讲,能获得使用者信任的系统通常具备透明(操作对用户可见)、可信(用户认可系统输出)、可审计(系统可被评估)、可靠(系统按用户期望行动)、可恢复(用户必要时能恢复控制)等特征。
通常而言,人工智能系统能力越强、与人类联系越紧密,使用者就越要高度信任它。在当前以及未来相当长的时期内,人工智能系统面临的重大挑战始终是软件生产质量不稳定。人工智能技术不断发展,使得人类与人工智能系统的联系愈发紧密。与此同时,我们要跟上并预估人工智能能力的日益进步,为人工智能的最佳实践制定管理原则与政策,还要对操作人员开展安全操作培训,这些都是提升使用者对人工智能信任度的必要措施。
可验证(Verification)即确定系统符合正式规范。该验证工作通常由厂商开展。厂商在完成产品生产后,需确认产品达到既定的正式规范,此规范可以是厂商自定的产品规范,也可以是行业或国家标准。
可确认(Validation)即判定系统可满足用户操作需求。确认通常由用户执行,用户拿到产品后,确认该产品能满足自身实际需求。
大家或许都知晓以ISO起始的国际标准、GB开头的国家标准之类的标准。这些标准让不同厂商能够制造出基本功能与质量差别不大的产品。人工智能产品属于新生事物,行业与国家规范有所缺失,用户也未必熟悉产品的各项功能,所以在可验证与可确认方面还有大量工作要做。通常,产业发展会早于标准的制定。当下正是开展一些人工智能产品标准制定工作的时候,我们也欣喜地看到人工智能产业界已经在努力了。
人工智能系统的安全性需要新的评估、诊断和修复方法。评估是确定系统是否故障(如在预期参数外运行),诊断是明确故障原因,修复则是调整系统解决故障。对于长时间自主运行的系统,设计人员可能未考虑到所有意外情况,所以这类系统或许要具备自我评估、诊断和修复能力才能稳健、可靠。
在关键系统里工作的人工智能系统务必要具备鲁棒性,这样才能应对各类意外与突发状况,同时还得能抵御形形色色的蓄意攻击。产品安全工程要贯穿于产品的设计、开发、运行和维护的全过程。人工智能系统面临的安全威胁,一部分与传统信息安全相同(如本书第2章内容所述),还有一部分安全风险是人工智能系统所特有的(如对抗样本,本书第3章会详述)。
人工智能系统或许最终会达到循环自我改进的状态,届时它能自行改进,无需人类程序员介入。一旦如此,其发展将更为迅猛,甚至可能失控。为保障这些可自我修改与进化的人工智能系统的安全,我们需要探索新的研究方向——自监测架构。
自监测架构可检测系统行为与人类设计者初始目标是否一致。人工智能能力不断提升,我们得让其与人类目标相符。自监测架构可视为人工智能系统里的免疫子系统,就像人类的免疫系统会时刻检测人体健康状况,消除不利因素对人体的威胁一样。自监测架构也能随时消除对初始目标有害的偏差,它能确保人工智能的发展与人类设定的初始目标保持一致。
自监测架构对保障未来人工智能系统安全而言必不可少。但当前,相关研究尚处初级阶段,还有大量工作有待开展。
点此查看本书详细情况。