ChatGPT等大模型在生活、科研和工作中作用显著,但训练代码通常不公开,仅提供专用接口或推理代码。
最近,OLMo开源了!这是目前最先进的开放语言模型框架,包含完整训练数据、代码、中间模型及日志,真正实现全面开放。
在训练与建模方面,OLMo 提供了完整的模型权重、训练代码、训练日志、剪枝信息,以及以 Weights & Biases 日志形式记录的训练指标和推理代码。此外,OLMo 首次推出了四个不同架构、优化器及训练硬件的 7B 规模语言模型变体,还有一个 1B 规模的模型,所有模型均至少经过 2T Token 的训练。同时,项目还在 HuggingFace 上分享了数百个中间检查点作为修订版本,便于研究者使用和改进。
OLMo涵盖数据集构建与分析的完整训练数据及生成训练数据的代码,适用于相关模型。
在评估方面,OLMo采用AI2的Catwalk进行下游任务评估,同时使用Paloma进行困惑度评估。
针对微调,OLMo推出了Open Instruct,不久后还将发布基于其调整的OLMo版本。所有代码与权重均以Apache 2.0许可开放。这为大模型的定制化应用提供了更多可能,促进开源社区的发展。
下面一起来看看这项研究吧。
OLMo:加速语言模型的科学研究进展,探索更高效的模型发展路径。
作者:Dirk Groeneveld等人
机构包括艾伦人工智能研究所、华盛顿大学、鲁大学、纽约大学和卡内基梅隆大学。
代码地址:https://github.com/allenai/OLMo,这是一个值得探索的开源项目,欢迎访问。
权重链接已提供,详见:https://huggingface.co/allenai/OLMo-7B,欢迎访问获取更多信息。
数据链接:https://huggingface.co/datasets/allenai/dolma,这是一个高质量的数据集,可供研究和开发使用。
评估链接:https://github.com/allenai/OLMo-Eval,这是一个用于评估语言模型的资源库。
微调链接已提供,详情请查看:https://github.com/allenai/open-instruct,欢迎访问并获取更多信息。
语言模型(LMs)已在自然语言处理的研究与实际应用中占据核心地位。随着其商业价值不断提升,最强大的模型逐渐被封闭在专有接口后,训练数据、模型架构及开发过程中的关键细节均未公开。然而,在研究这些模型时,尤其是探讨其潜在偏见和风险时,这些信息至关重要。因此,我们认为研究界需要能够获取功能强大且完全开放的语言模型。
在此背景下,本技术报告正式发布OLMo,这是一款领先且真正开源的语言模型,同时包括用于构建和研究语言建模的完整框架。不同于以往仅提供模型权重和推理代码的做法,我们此次发布了OLMo的全部内容,涵盖训练数据、训练代码及评估代码。我们希望通过这一全面开放的举措,助力并强化开放研究社区,激发新一轮的技术创新浪潮。
以下是OLMo发布的全部内容:
训练与建模代码位于:https://github.com/allenai/OLMo,可供访问和使用。
7B模型链接:https://huggingface.co/allenai/OLMo-7B,可供访问。
OLMo-7B-Twin-2T模型:https://huggingface.co/allenai/OLMo-7B-Twin-2T,该模型由allenai提供,适用于多种自然语言处理任务。
1B模型:https://huggingface.co/allenai/OLMo-1B 提供了训练好的模型权重,可供下载使用。
所有模型均发布最终权重及500多个每1000步间隔的Checkpoint。
训练数据Dolma来自https://huggingface.co/datasets/allenai/dolma,可供研究使用。
Dolma 是一套用于构建新数据集的工具包,其项目地址为:https://github.com/allenai/dolma。此外,还提供了 WIMBD 工具,用于数据集分析,地址为:https://github.com/allenai/wimbd。这两个工具可助力数据集的开发与研究工作。
下游任务评估的代码位于以下链接:https://github.com/allenai/OLMo-Eval。其中,使用了Catwalk工具(https://github.com/allenai/catwalk)进行评估,同时借助Paloma平台(https://paloma.allen.ai/)完成困惑度(perplexity)评估。这些工具共同为模型性能提供了全面的分析手段。
作者打算尽快发布新版本,包含以下内容:
OLMo 使用解码器专属 Transformer 架构,有 1B 和 7B 两种变体,65B 版本即将发布。
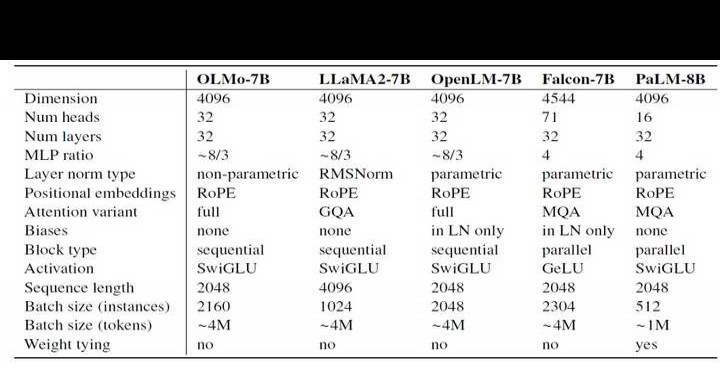
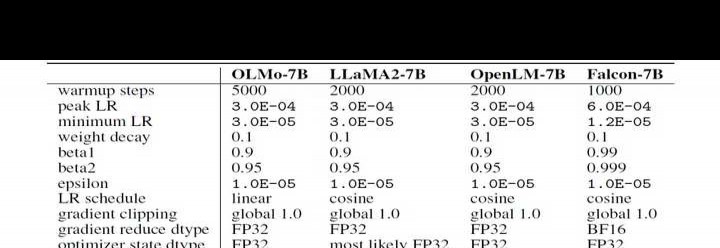
大语言模型一般通过优化硬件训练吞吐量,同时尽量减少峰值丢失和缓慢发散风险来选取超参数。下表对比了OLMo的设计决策与当前最新的开源语言模型。OLMo对原始Transformer架构的主要改动可概括为以下几点:
无偏置设计。如同LLaMA、PaLM等模型,我们去除了架构中的所有偏置项,从而提升训练稳定性。
(2)无参数的层归一化。采用不包含仿射变换的层归一化方式,即不使用自适应增益或偏置。作者认为这种方式最为稳妥,且相比参数化层归一化和 RMSNorm,运行速度更快。
采用 SwiGLU 激活函数。和 LLaMA、PaLM 等模型相同,使用 SwiGLU 而非 ReLU 作为激活函数。根据 LLaMA 的设计,激活隐藏层尺寸约为 8/3d,但会调整为最接近的 128 的倍数,以优化吞吐量表现,例如在 7B 模型中为 11008。
(4)旋转位置嵌入(RoPE)。如同LLaMA、PaLM等模型,以旋转位置嵌入替代绝对位置嵌入。
词汇表采用修改版的GPT-NeoX-20B基于BPE的分词器,新增了用于屏蔽个人可识别信息(PII)的特殊标记,最终词汇量为50,280。然而,为提升训练吞吐量,模型中对应的嵌入矩阵尺寸调整为50,304,使其成为128的倍数,从而优化计算效率与性能表现。
尽管在获取模型参数方面有所进展,但预训练数据集的开放性依然不足。通常情况下,这些数据集不会与开源模型一同发布,更别说是闭源模型了。此外,关于数据集的文档往往缺乏足够的细节,难以实现工作的复现或深入理解。这给语言模型研究中的某些方向带来了困难,例如探索训练数据如何影响模型的能力与局限性。为了推动语言模型预训练的开放研究,OLMo 创建并发布了名为 Dolma 的预训练数据集。该数据集包含来自 7 个不同数据源的 50 亿文档中的 3 万亿 Token,形成一个多样化且多源的语料库。这些数据源不仅在大规模语言模型预训练中广泛使用,而且对公众开放访问。
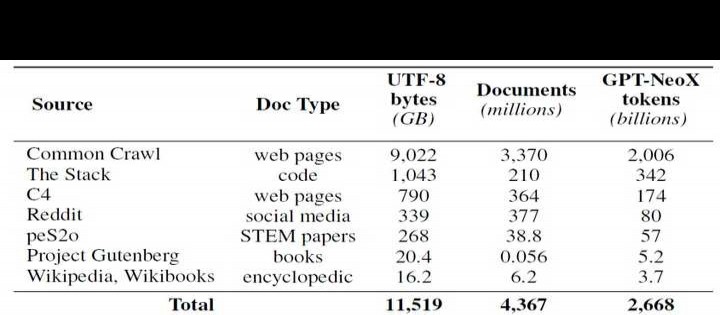
Dolma 数据集的构建流程包括六个步骤:(1)语言过滤,(2)质量过滤,(3)内容过滤,(4)去重,(5)多源混合,以及(6)分词。此外,还提供了在 Dolma 中间状态上训练语言模型的分析与实验结果。在整个处理过程中,作者确保每个来源的文档始终保持独立,并在最终发布时依然如此。同时,他们开源了高性能的数据处理工具,该工具包可用于进一步实验、复现研究,以及快速高效地整理预训练语料库。为了辅助数据集分析,作者还开源了 WIMBD 工具。
模型评估分两阶段:在线评估辅助设计决策,离线评估检验模型检查点。
离线评估采用公开的 Catwalk 框架,该工具可广泛访问多种数据集和任务格式。利用 Catwalk 进行下游任务评估,同时针对新的 Paloma 困惑度基准开展内在语言建模评估。在下游与困惑度评估中,使用作者设定的固定评估流程,并与多个已公开模型进行对比分析。这种方法确保了评估结果的一致性和可比性。
循环内训练消融:在整个模型训练期间,通过下游评估来决定模型架构、初始化方式、优化器选择、学习率调度及数据混合策略。这种方法被称为在线评估,因为每经过1000步训练(约40亿个训练令牌),便会运行一次评估,从而为模型训练质量提供早期且持续的反馈信号。
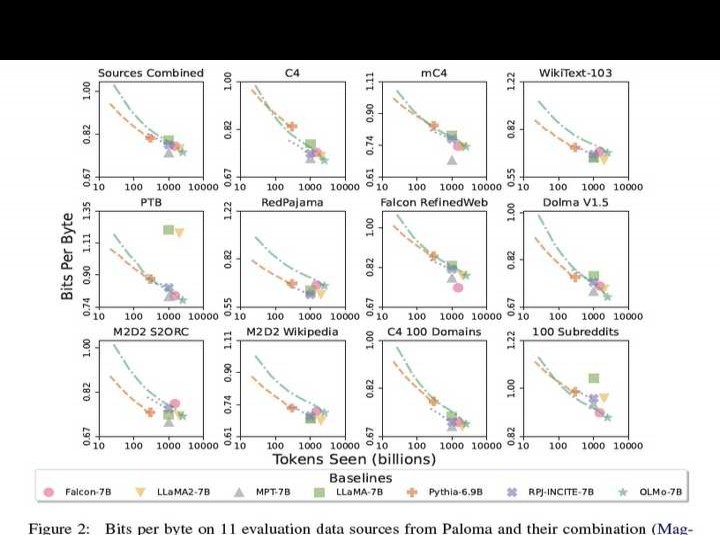
作者的目标不仅在于将 OLMo-7B 与其他模型进行性能对比,还在于展示其如何实现更加全面且可控的科学评估。OLMo-7B 是目前在明确去污染条件下进行困惑度评估的最大语言模型。根据 Paloma 所述方法,作者移除了所有可能泄露至 Paloma 评估数据中的预训练文档段落。若不进行去污染处理,其他模型可能会低估困惑度(即高估模型对未知数据的适应能力)。此外,作者还公开了中间检查点,从而能够与另外两个发布检查点的模型开展更为丰富的对比分析。这一举措有助于更深入地理解模型的特性及其改进空间。
OLMo采用ZeRO优化器策略,借助PyTorch的FSDP框架完成模型训练。此框架通过在GPU上对模型权重及其对应的优化器状态进行分片,有效降低内存消耗。在7B参数规模下,可在每个GPU上以4096个标记的微批量大小开展训练。
针对OLMo-1B和OLMo-7B模型,使用大约4M标记(由2048个实例组成,每个实例序列长度为2048标记)的固定全局批量大小。而对于正在训练中的OLMo-65B模型,则采用批量大小逐步预热的方式:从约2M标记(1024个实例)开始,每积累100B标记后将批量大小翻倍,最终达到约16M标记(8192个实例)。
为了进一步提升训练吞吐量,模型使用混合精度训练方法。该方法通过FSDP内置配置与PyTorch的amp模块实现。其中,amp模块确保诸如softmax等关键操作始终以全精度运行,从而增强数值稳定性;而其他大部分操作则以半精度bfloat16格式执行,兼顾效率与性能。
OLMo采用AdamW优化器进行训练。对于各种规模的模型,学习率在5000步(约21亿个令牌)内逐渐升高,随后线性衰减到峰值的十分之一,直至训练结束。预热阶段后,对梯度进行裁剪,确保参数梯度的总体l2范数不超过1.0。

训练数据集源自作者开源的Dolma数据集,使用2万亿令牌样本构建。每个文档的令牌会在末尾添加特殊的EOS标记后串联,再将连续2048个令牌划分为一个训练实例。每次训练时,都会以相同方式打乱这些实例的顺序。所有发布的模型均接受了至少2万亿令牌的训练。
为确保代码库在NVIDIA和AMD GPU上性能无损,分别在两个不同集群训练了模型。
LUMI由LUMI超级计算机支持,该集群最多启用256个节点,每节点配备4块AMD MI250X GPU,内存128GB,互联带宽达800Gbps。
MosaicML:此集群包含27个节点,每节点配备8张NVIDIA A100 GPU,单卡显存40GB,节点间互联带宽达800Gbps。
虽对批量大小稍作调整以优化训练吞吐量,但两次运行在2T令牌评估时性能几乎相同。
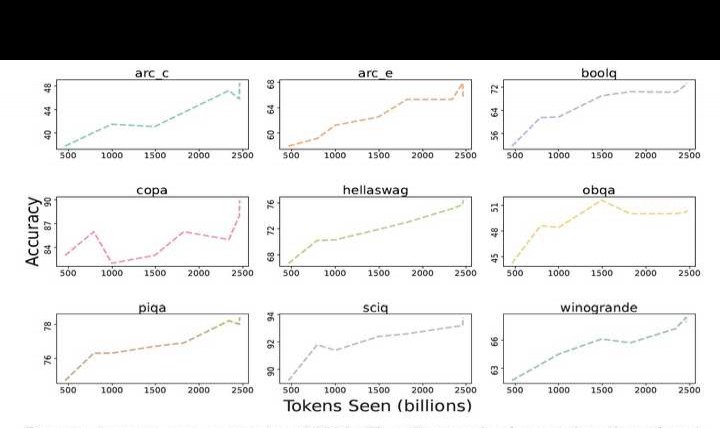
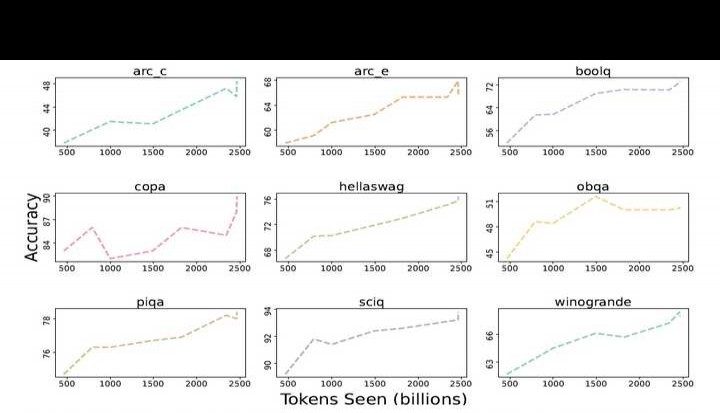
核心下游评估套件包含以下内容:arc(分为arc easy与arc challenge)、boolq、openbookqa、sciq、hellaswag、piqa、copa以及winogrande。研究者对OLMo-7B进行了零样本测试,并将其结果与另外6个规模相近的开源模型进行对比分析。结果显示,OLMo-7B检查点在2项任务中表现突出,并且在评估套件涵盖的8/9项任务中稳居前三名。从整体来看,相较于其他6个公开模型检查点,OLMo-7B展现出较强的竞争力。
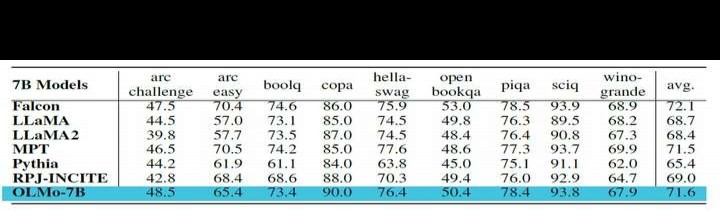
9个核心任务的准确性分数呈现不同进展。除OBQA外,其余任务在OLMo-7B训练更多令牌时均呈上升趋势。最后两步之间,多个任务准确性显著提升,表明线性降低学习率至0的最后1000步训练带来了明显收益。
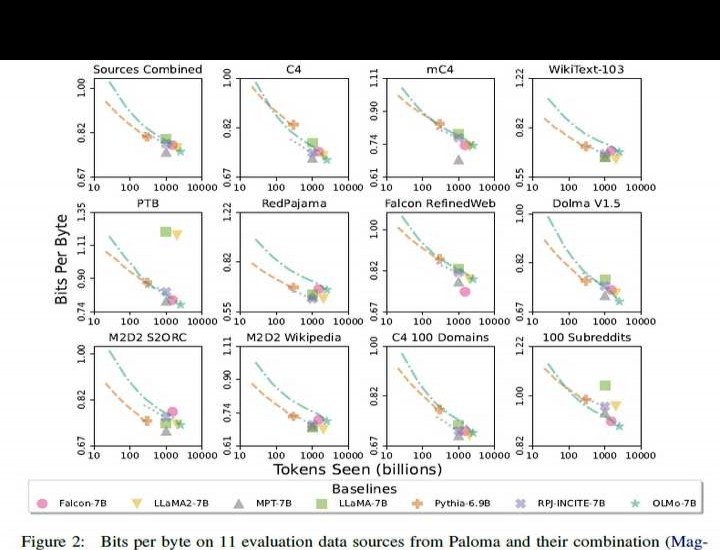
在内在评估方面,Paloma不仅分别考察各个领域的表现,还对18个数据源的组合进行了综合分析。2中Sources Combined子图所示,OLMo-7B在基于Paloma的11个数据源组合上的表现,与6个规模相近的语言模型进行了对比。从结果来看,OLMo整体竞争力较强,尤其考虑到其训练数据经过了Paloma的专门优化和净化处理,这一表现更加突出。
作者开源了首个版本的OLMo,这是一款真正开放且先进的语言模型及其配套框架,旨在推动语言建模科学的发展。与以往大多仅提供模型权重和推理代码的做法不同,此次不仅发布了OLMo模型,还公开了完整的框架,包括训练数据、训练与评估代码。后续还将分享训练日志、消融实验结果、研究成果以及Weights & Biases记录。同时,团队正在尝试通过指令微调和多种RLHF变体对OLMo进行优化。最终,所有经过适应的模型、相关代码及数据都将对外发布,以促进更广泛的研究与应用。
作者计划不断支持和发展OLMo及其框架,进一步拓展开放语言模型的边界,提升开放研究社区的实力。未来将把不同规模、模态、数据集、安全机制及评估方法融入OLMo系列中。
关注公众号3D视觉工坊,掌握工业3D视觉、自动驾驶、SLAM、三维重建等领域前沿动态与论文资讯。
一种结合NeRF和高斯模型的全新SLAM算法,提升场景重建精度与效率。
移动机器人规划控制入门实践:基于Navigation2系统
自动驾驶未来:BEV和Occupancy网络全景解析与实践探索
4、Python在三维视觉中的入门与实战应用