最近抽空参加了CCF举办的RAG比赛,在比赛中系统性地测试和对比了RAG检索中的多种优化方案,同时挖掘出不少之前未曾留意的优化细节。从实际操作来看,这类比赛确实是检验策略的理想平台,能够公平且客观地对不同优化方法进行比较。在实践过程中,我们时常会发现一些看似高效的策略却收效甚微,而某些毫不起眼的方法反而表现出色。通过结果逆向剖析这些策略,可以更清晰地理解每种策略适用的场景及其优劣所在,这也有助于我们识别自身技能的不足之处。
最近偶然看到 AIOps RAG 比赛的优胜方案 EasyRAG,该方案在初赛中夺得第一名,复赛位列第二名。其相关代码已开源至 Github。我利用空闲时间仔细研读了相关论文与实现细节,并将整理后的内容分享于此。
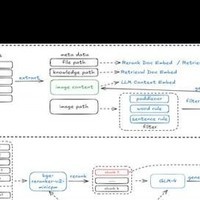
整体方案如下:
图中显示,整体方案主要分为两部分:
整个框架依托 llama-index 构建。当前而言,llama-index 是一款出色的 RAG 基础框架,能够助力快速搭建 RAG 服务。对此感兴趣的同学们可以深入探究一番。
下面将介绍EasyRAG的部分技术细节,有兴趣的读者建议参考原始论文和Github代码。
在分片构建时,EasyRAG通过加入元信息(如知识库路径、文件路径等),有效提升了检索召回率。实际测试结果显示,添加元信息后,模型准确性提高了2%。这一优化对性能改进具有积极意义。
实践中发现,加入元信息后,llama-index 在计算块大小和重叠大小时存在缺陷。为解决此问题,手动实现了 SentenceSplitter,并通过 Easyrag splitter 完成了相关修复,具体实现可前往查看。
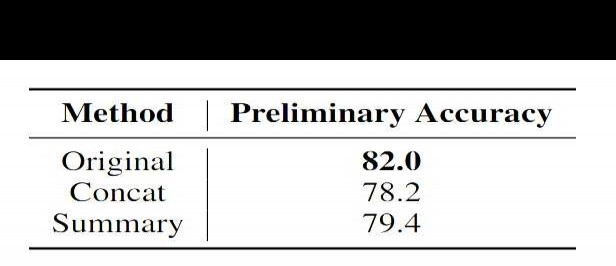
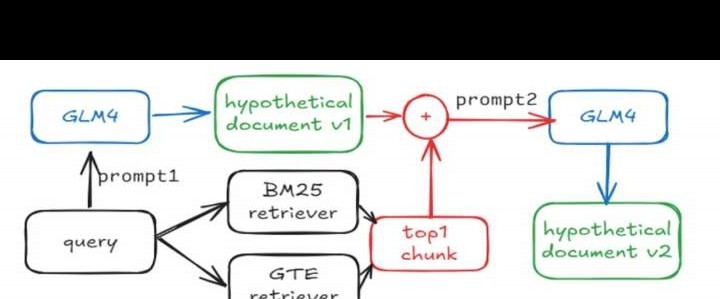
HyDE旨在应对问题与文档答案相似度低的情况,但用它生成常规问题时,容易产生大量无关的冗余信息,严重影响检索质量。为此,在流程中将HyDE生成的文档与检索出的Top1文档结合,构建更贴近实际知识库的假设文档,理论上可改善原HyDE的不足。然而,实际测试结果仍然不尽人意,效果提升有限。这表明仅靠简单融合可能无法根本解决HyDE存在的核心问题。
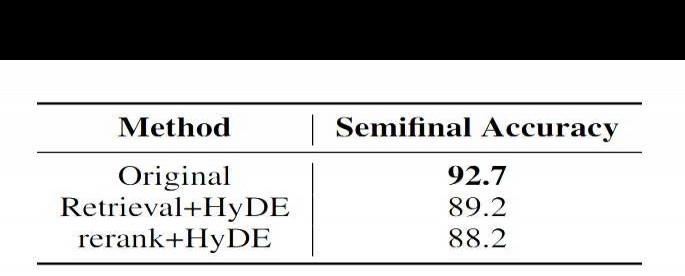
此外,利用 HyDE 生成的文档进行检索和重排序,效果不如直接用原始问题。该方法类似于 RAG + R,在特定场景下相比原生 HyDE 或有提升,后续可尝试验证。
文档检索采用双路 BM25 加向量检索方案,双路 BM25 包括文档块与路径检索。以下是实际应用中的部分优化策略:
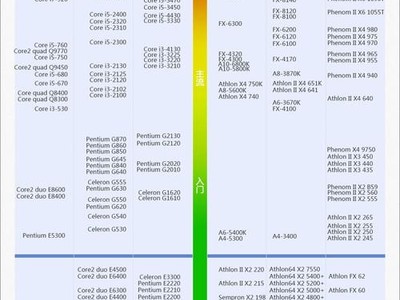
经过多次实验,我们发现基于LLM构建的模型bge-reranker-v2-minicpm-layerwise表现最优,这与我们的实际测试结果一致。以下是具体测试情况:
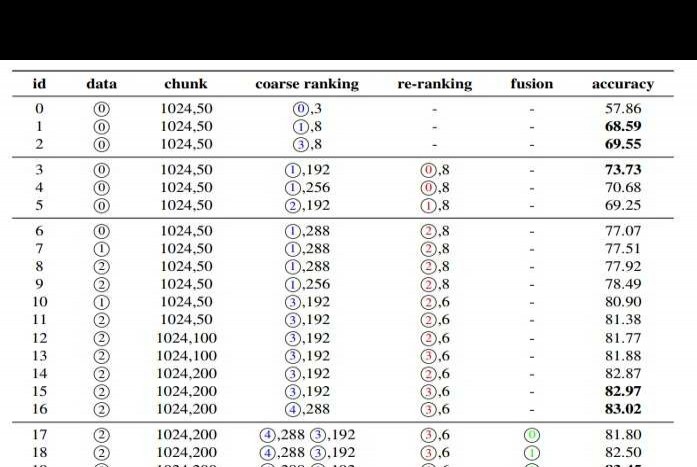
请留意重排序列,其中用到的模型编号如下:
从实际数据来看:
28层的bge-reranker-v2-minicpm-layerwise表现优于40层的同类模型,同时也优于bge-reranker-v2-m3和bce-reranker-base_v1。这一结果与我们在其他数据集上的测试结论一致,证明了模型在不同情况下的稳定性及有效性。这种层次间的性能差异可能与参数调整、训练策略等因素相关。
采用多种混合检索方式,需融合多路结果,以下为实际尝试的方案:
上述方法等同于下方融合策略中的 2、3、4 号方案,其对结果影响较小。就可靠性和通用性而言,通常仍建议采用 RRF 方法。
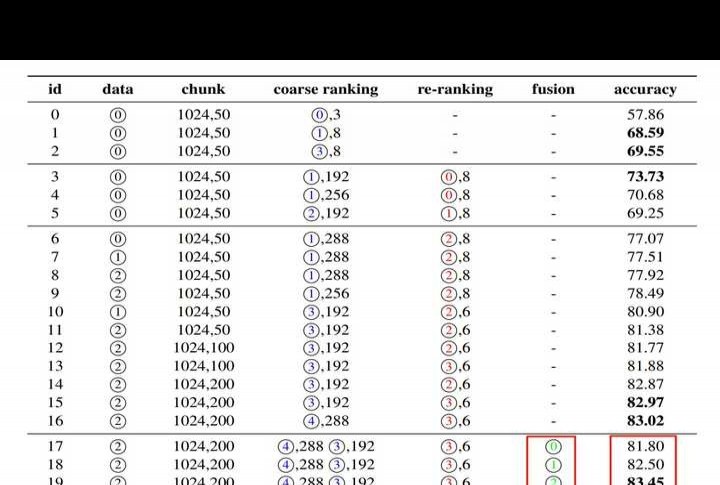
这个方案或许对比赛预期有一定效果,毕竟比赛中答案常集中在特定范围内。若重排序表现优秀,通常 Top1 就是正确答案。不过,该方案在普通情况下是否真的有效,仍需进一步验证。
EasyRAG 采用基于 BM25 的压缩方法,实现较为简单。它将检索内容按句拆分,利用 BM25 计算查询与每句的相似度,再按相似度从高到低依次加入列表,直至达到预设压缩率。该方法已与 LLMLingua 对比测试,结果显示效果较为理想。

本文全面介绍了EasyRAG方案,该方案融合了多种RAG优化策略。尽管其设计更偏向竞赛场景,可能存在为提升效率而牺牲准确性的情况,从而难以直接应用于生产环境,但仍具一定启发性,值得在实际应用中探索与尝试。