本文对ISSCC(固态电路)-2024会议里领军企业与高校的20篇实用论文进行了梳理和总结,可供学习、科研、工作参考。
2.1 基于5G移动片上系统(SoC)的4纳米、3.4吉赫兹三档完全乱序ARMv9.2 CPU子系统。
名称:5G移动SoC,其基于4nm、3.4GHz的Tri - Gear完全乱序ARMv9.2 CPU子系统。
论文链接:https://ieeexplore.ieee.org/document/10454494。
单位为联发科(MTK)。
ISSCC 2024会议。
摘要:
本文是为即将上市的旗舰智能手机所撰写,阐述了一种全新的三档CPU子系统,此系统意味着移动SoC发生了范式转变。尽管三档CPU子系统已被发布,但该成果是首个在集群的全部三个档位都运用乱序(OoO)CPU的成果发布。此系统采用4nm CMOS工艺,由四个乱序高效(HE)内核、三个平衡性能(BP)内核以及一个高性能(HP)内核作为辅助。极为关键的是,全硬件动态电压和频率调节(DVFS)控制是通过对之前工作中的DVFS控制机制加以强化来达成的。
借助SRAM电源的自动双轨均衡器以及核心电源的新型高带宽电压控制器(HBVC),所有软件对电源排序的依赖得以消除。更快的响应时间以及利用PMIC中的省电模式能够实现功耗方面的优势。全CMOS单轨存储器用于频繁访问的一级缓存(L1$),可大幅节省功耗,同时,降低中层标准单元电阻和电容的布局技术能提高最大时钟频率。芯片照片见图2.1.7,单线程功率和性能比较见图2.1.1。
2.2 Zen 4c:AMD的5纳米面积优化型×86 - 64微处理器核心。
名称:2.2Zen 4c,AMD 5nm、面积优化的x86 - 64微处理器核心。
论文链接:https://ieeexplore.ieee.org/document/10454507。
AMD这个单位。
ISSCC 2024会议。
摘要:
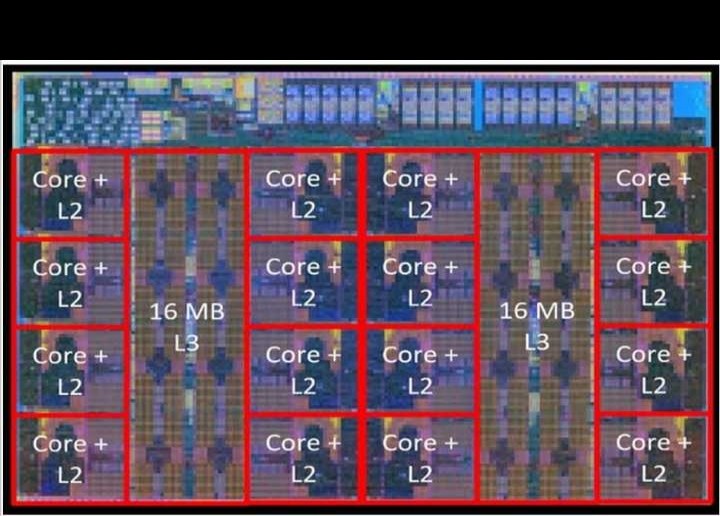
Zen 4c属于AMDZen微处理器系列,是该系列中首个采用面积优化设计的产品,主要面向云计算等对节能和核心密度要求较高的应用。在同样的5nm FinFET工艺技术下,Zen 4c微处理器核心(包含专用L2缓存)的面积比Zen 4要小35%。由于每个核心共享的L3缓存数量从4MB降到了2MB,Zen 4c核心复合芯片(CCD)的核心数量达到了Zen 4CCD的两倍,而且二者的L3缓存总量相同,均为32MB,这使得每个插槽的内核数量最多可增加33%。这种面积优化让Zen 4c每毫米性能提升超过25%,与Zen 4相比,SPECrate®2017_int_base的性能/功耗提高了9%。Zen 4c在服务器配置下能以高达3.1GHz的频率运行,并且性能更节能。图2.2.1展示了基于Zen 4c的CCD,其包含73mm的9.0B晶体管,由两个核心复合体(CCX)组成,每个核心复合体有八个Zen 4c核心和16MB的L3缓存。
2.3 Emerald Rapids:第五代英特尔®至强®可扩展处理器。
名称:2.3 Emerald Rapids,这是第五代Intel® Xeon®可扩展处理器。
论文链接:https://ieeexplore.ieee.org/document/10454434。
英特尔(Intel)公司。
ISSCC 2024会议。
摘要:
第五代Intel Xeon可扩展处理器(代号为Emerald Rapids),其内核数量可达64个,共享L3缓存超过300MB,拥有8个DDR5通道(1DPC 5600MT/s)、32GT/s的PCIe/CXL通道、20GT/s的UPI通道,由多芯片封装中的2个芯片构成(2.3.1所示)。相较于第四代Xeon处理器,这一代在相同功耗的情况下,一般整数计算工作负载的性能提升了18%,浮点工作负载的性能提升了24%。
这一成果的达成,是通过对内核加以改进、提升工艺技术、增多内核数量、大幅增加缓存、加快DDR内存速度、削减芯片数量,并且提高空闲状态下的电源效率等方式实现的。其制造运用了针对服务器使用进行优化的Intel 7工艺技术,这种技术提高了晶体管速度,重点关注减少泄漏和动态电容,与上一代工艺修订版相比,频率/瓦提高了3%。空闲时电源效率的关键改进在于对完全集成稳压器(FIVR)的改进,从而减少利用率低时的稳压器损耗、强化主动空闲检测与节能以及降低封装C6功耗。
2.4 ATOMUS:用于对延迟要求严苛的应用的5纳米、32TFLOPS/128TOPS的机器学习片上系统。
名称:2.4 ATOMUS,这是适用于对延迟要求高的应用的5nm、32TFLOPS/128TOPS的机器学习片上系统。
论文链接:https://ieeexplore.ieee.org/document/10454509。
单位:叛乱(复数形式)
ISSCC 2024会议。
摘要:
人工智能推理的计算需求不断增长,使得硬件加速器被广泛应用于从边缘到数据中心/云的不同平台。在高频交易(HFT)等部分人工智能应用领域,成功执行有着严格的推理延迟期限。
我们全新推出了一款AI加速器。它有着高推理能力与优秀的单流响应能力,能满足要求严格的基于服务层目标(SLO)的AI服务以及流水线推理应用程序的需求,大型语言模型(LLM)也包含在内。
横向扩展解决方案因热设计功耗(TDP)低,能有效支持多流应用和以总拥有成本(TCO)为核心的系统。

2.5A、基于28纳米物理的光线追踪渲染处理器,用于移动设备上具有逆渲染和背景聚类的逼真增强现实。
2.5 28nm基于物理的光线追踪渲染处理器,用于移动设备,可实现逆向渲染与背景聚类,增强现实感。
论文链接:https://ieeexplore.ieee.org/document/10454394。
西北大学这一单位。
ISSCC 2024会议。
摘要:
增强现实(AR)和虚拟现实(VR)的应用正迅速拓展,这使得增强视觉真实感的需求持续增加。在新兴的AR应用为工作场所或家庭提供实时视觉辅助时,逼真的图像生成与插入是其基本功能。基于物理的光线追踪(PBRT)常被用于生成合成图像,它通过模拟真实环境并追踪光传输来实现反射、折射、软阴影等真实感效果,在产品设计、医学可视化、视频游戏和电影特效方面被广泛运用。要达成照片级的真实感渲染,移动设备对光线追踪(RT)的支持是极为必要的。
然而,面临的挑战包括:其一,非结构化的内存访问模式与复杂的控制流程使得调度工作难以开展;其二,高内存需求会耗尽边缘设备有限的SRAM空间;其三,误差容限低,对计算精度要求高;其四,像除法和平方根这样复杂的计算,需要边缘设备投入大量计算资源。所以,Apple ARKit、OpenGL等常见的渲染引擎主要采用成本较低的光栅化渲染技术。但遗憾的是,光栅化渲染无法生成逼真的合成效果,2.5.1所示。截至目前,很少有专为移动真实感渲染解决方案而制造的ASIC,而且它们可能不支持RT,或者效率低下。
这项工作研发出一种光线追踪处理器,该处理器还能支持用于背景提取的逆渲染(IR)。这项工作具备以下主要特性:其一,它是一种ASIC渲染处理器,能在移动设备上嵌入带有IR的端到端PBRT解决方案;其二,其可重新配置的混合精度PE设计,可支持IR的多种计算任务与光线追踪(RT);其三,构建以背景集群视场(FOV)为核心的3D结构,将传统背景场景的复杂度从O(nlogn)降至O(1);其四,针对复杂3D对象有可扩展分区方案,在平均成本为13美元的测试场景下实现加速;其五,运用全局光线追踪调度器(GRTS)和全局内存访问控制器(GMAC)来应对不规则内存访问模式和不同PE运行时间等挑战,总体加速达684倍(相较于基线设计)。与现有的ASIC解决方案相比,28纳米测试芯片的渲染效率提高了3.95美元 - 28.8倍,能够在移动边缘设备上达成实时PBRT渲染。

2.6A、131mW、6.4Gbps、256×32多用户MIMO OTFS检测器用于下一代通信系统。
2.6 131mW、6.4Gbps、256×32多用户MIMO OTFS检测器,适用于下一代通信系统。
论文链接:https://ieeexplore.ieee.org/document/10454410。
单位:台湾大学。
ISSCC 2024会议。
摘要:
2.6.1所示,未来的无线系统将容纳高铁、无人机(UAV)、低地球轨道(LEO)卫星等各类高移动性设备。在这种快速时变的信道条件下,当前正交频分复用(OFDM)系统的性能会因严重的多普勒扩展所引发的载波间干扰而下降。正交时频空间(OTFS)系统被视作高移动通信的一个颇具前景的解决方案。OFDM是在时频(TF)域复用数据符号,而OTFS则在延迟多普勒(DD)域复用。在OTFS系统里,传输数据通过逆辛有限傅立叶变换(ISFFT)和海森堡变换来调制,接收数据借助辛有限傅里叶变换(SFFT)和维格纳变换进行解调。等效的DD域信道能反映无线环境的物理几何形状,对多普勒扩展有很强的适应性。OTFS技术与大规模多用户多输入多输出(MU - MIMO)相结合,有望满足未来高吞吐量、高移动性通信系统日益增长的需求。
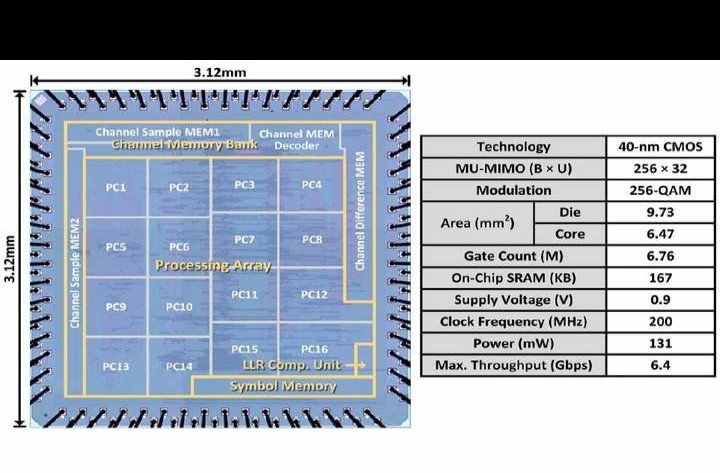
2.7 BayesBB:一款速率达9.6Gbps、延迟为1.61ms的可配置全消息传递基带加速器,适用于40nm CMOS工艺下的B5G/6G无蜂窝大规模MIMO。
名称:2.7 BayesBB,这是一种用于B5G/6G无单元大规模MIMO的基带加速器。它采用40nm CMOS,速率达9.6Gbps,耗时1.61ms,可配置且全消息传递。
论文链接:https://ieeexplore.ieee.org/document/10454287。
单位为东南大学。
ISSCC 2024会议。
摘要:
5G无线网络在全球范围内取得的成功给人类生活带来了重大影响。在即将来临的超5G(B5G)与6G时代,无线网络要从消费类应用朝着以生产为中心的需求发展,从而为各个垂直行业提供全方位的支持。所以,无蜂窝大规模MIMO成了B5G/6G的关键推动因素,能够提供更高的频谱效率(SE)。B5G/6G希望基带(BB)芯片既能提供更高的吞吐量(每个用户高于8Gbps),又有超低延迟(低于2毫秒),还能灵活支持多种应用(具备良好的可配置性)。
目前的文献大多着重于单独的BB模块,像是MIMO检测器、信道解码器或者它们的组合。所以,B5G/6G需要一种系统级的BB芯片,这种芯片要能在高吞吐量、低延迟以及对各类应用的适应性方面,提供让人满意的性能。2.7.1所示,使用这种系统级BB芯片会面临三个挑战:其一,实现高吞吐量是必要的,这就要求设计出高速接口,该接口既要能应对预期中的B5G/6G数据流量增长,又要符合IEEE 802.3标准;其二,确保低延迟颇具挑战性,这需要把多种算法整合到单个BB芯片内,同时还要满足B5G/6G应用严格的时间要求;其三,达成卓越的可配置性很困难,因为这需要一个灵活的架构来服务B5G/6G领域的多个应用程序。
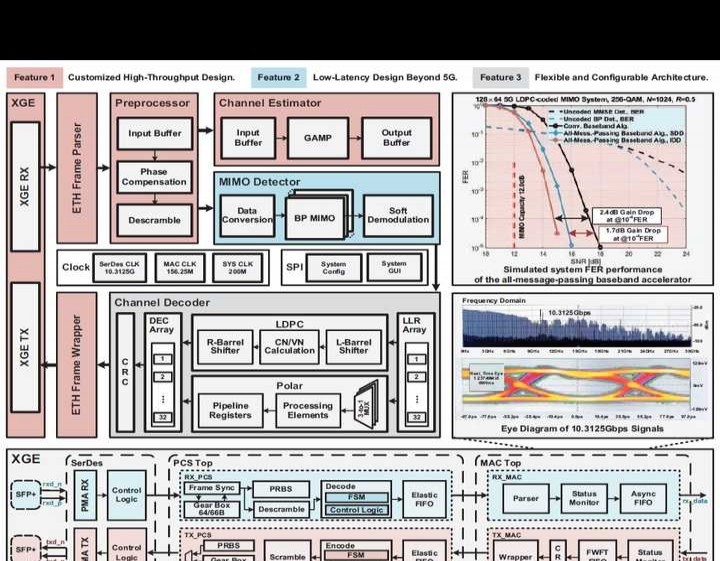

2.8A、21.9ns、15.7Gbps/mm²(128,15)的BOSS前向纠错(FEC)解码器,适用于5G/6G超可靠低延迟通信(URLLC)应用。
名称:2.8,15.7 Gbps/mm² (128,15) BOSS FEC解码器,适用于5G/6G URLLC应用,其解码时长为21.9ns。
论文链接:https://ieeexplore.ieee.org/document/10454363。
浦项科技大学(单位名称)。
ISSCC 2024会议。
摘要:
新兴的关键任务应用,像医疗保健监控、远程手术和自动驾驶等,要想实现的话,5G/6G超可靠低延迟通信(URLLC)设备就得同时具备超可靠、低延迟的特性。电力通信里的短数据传输也是如此(2.8.1所示)。但现有的URLLC设备短长度前向纠错(FEC)解决方案,没办法同时达到所有这些高要求。近期提出的短块长度和低速率块正交稀疏叠加(BOSS)码,被视为很有潜力的下一代FEC候选方案之一,它凭借低延迟和高可靠性,能够支持URLLC的所有特性。
这项工作充分利用BOSS代码的稳健纠错与低延迟特性,提出将BOSS解码器集成为URLLC FEC解决方案。我们的设计以较低的面积成本达成了更高的面积和能源效率,比最先进的URLLC FEC设计更具优势。
11.1 AMD Instinct™ MI300系列模块化小芯片封装——面向百亿亿级系统的高性能计算(HPC)和人工智能(AI)加速器。
名称:11.1 AMD Instinct MI300系列,其为模块化小芯片封装,是适用于Exa级系统的高性能计算(HPC)和人工智能(AI)加速器。
论文链接:https://ieeexplore.ieee.org/document/10454441。
AMD这个单位。
ISSCC 2024会议。
摘要:
AMD Instinct™ MI300系列加速器旨在从最新芯片与先进封装技术里挖掘出最大的高性能计算(HPC)和人工智能(AI)能力。它既能作为由CPU托管的PCle®设备MI300X运行,也能作为自托管的加速处理单元(APU)运行。AMD借助小芯片功能和先进封装技术,首次把数据中心级CPU、GPU加速计算、AMD无限缓存以及8堆栈HBM3内存系统集成到一个封装之中。AMD察觉到很多AI和HPC运营商受内存限制,所以将MI300的目标设定为提供超过5TBps的HBM3峰值带宽。

11.2 一种用于增强现实应用的3D集成原型片上系统:采用面对面晶圆键合、间距小于2μm的7nm逻辑工艺,在等面积占位下可实现高达40%的能耗降低。
名称:11.2 3D集成原型片上系统用于增强现实应用,采用面对面晶圆键合7nm逻辑,间距<2μm,同等面积下能耗最多可降低40%。
论文链接:https://ieeexplore.ieee.org/document/10454529。
梅塔单位。
ISSCC 2024会议。
摘要:
增强现实(AR)产品需要节能型片上系统(SoC)来满足机器学习(ML)、神经网络(NN)和图像信号处理(ISP)等应用需求。这类SoC需具备高性能、低功耗以及紧凑的外形,其占地面积受限严重,不过在三维空间通常有足够的空间。而且,对于AR设备而言,频繁访问片外存储器会在延迟和能耗方面付出高昂代价。
幸运的是,3D集成技术的最新进展使额外的逻辑和内存能够集成到SoC中,并且不会增加面积成本。特别是采用混合键合(HB)的面对面(F2F)堆叠方式,可实现芯片间的高带宽(BW)连接,且不会产生大量能耗。我们首次在AR领域展示了运用面对面混合键合技术的3D集成SoC,旨在表明:(1)部署更大的工作负载,由于之前受内存容量、外形尺寸基准限制以及严格的执行时间和能耗要求,这些工作负载在同尺寸基准下无法实现;(2)在严格的外形尺寸限制下,我们的AR SoC原型在系统级能耗和执行时间方面均有节省(各自节省幅度高达40%)。
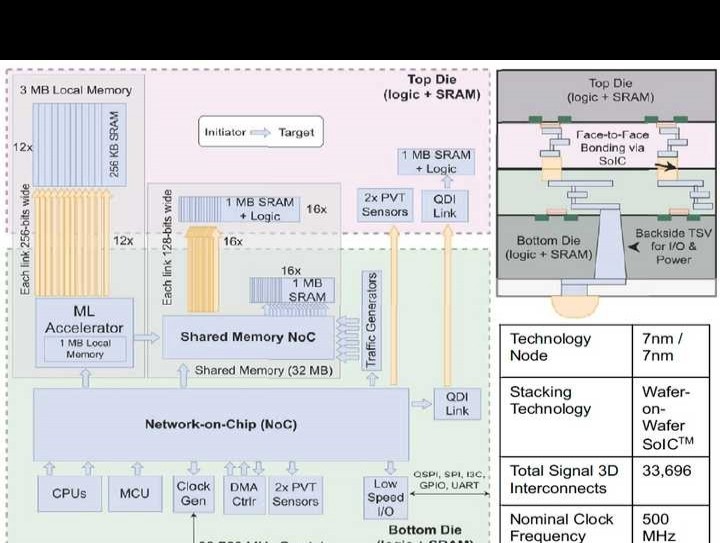
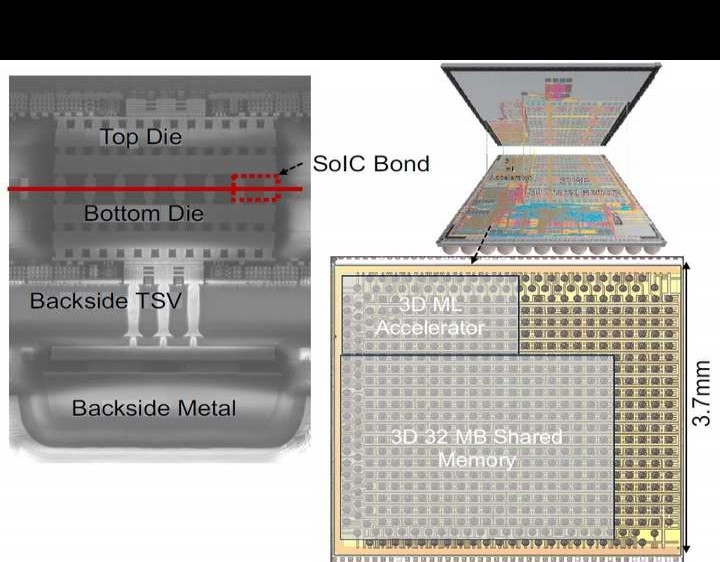
11.3 Metis AIPU:一款12纳米、15TOPS/瓦、209.6TOPS的系统级芯片(SoC),用于边缘端实现兼具成本效益与高能效的推理。
名称为11.3的Metis,其AIPU为12nm、15TOPS/W、209.6TOPS的SoC,可在边缘进行成本低且节能的高效推理。
论文链接:https://ieeexplore.ieee.org/document/10454395。
Axelera AI:相关单位名称。
ISSCC 2024会议。
摘要:
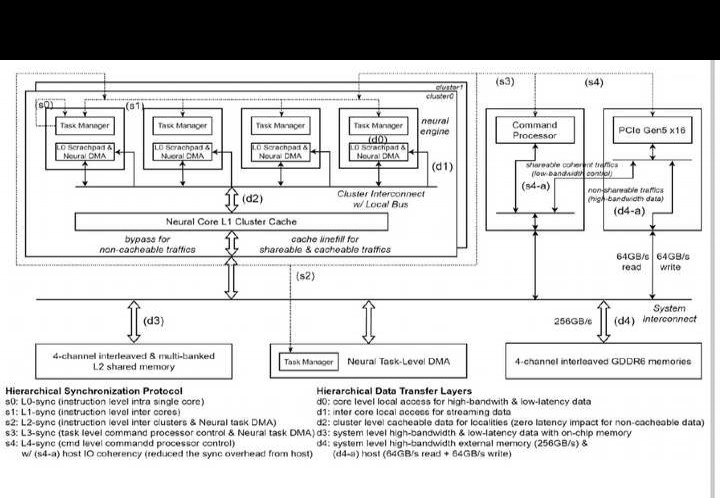
Metis AI处理单元(AIPU)属于四核片上系统(SoC),是为边缘推理打造的,能够在片上运行AI工作负载的所有组成部分。Metis AIPU里每个AI核心的性能可达52.4 TOPS,整体复合吞吐量为209.6 TOPS。图11.3.1展示了Metis AIPU的主要特性以及它和基于PCIe卡的系统的集成情况。Metis借助量化数字内存计算(D - IMC)架构的长处,这个架构有着8b权重、8b激活以及全精度累加的特点,从而降低权重和激活的内存成本,减少矩阵向量乘法(MVM)的能耗,并且不会对神经网络的准确性产生影响。
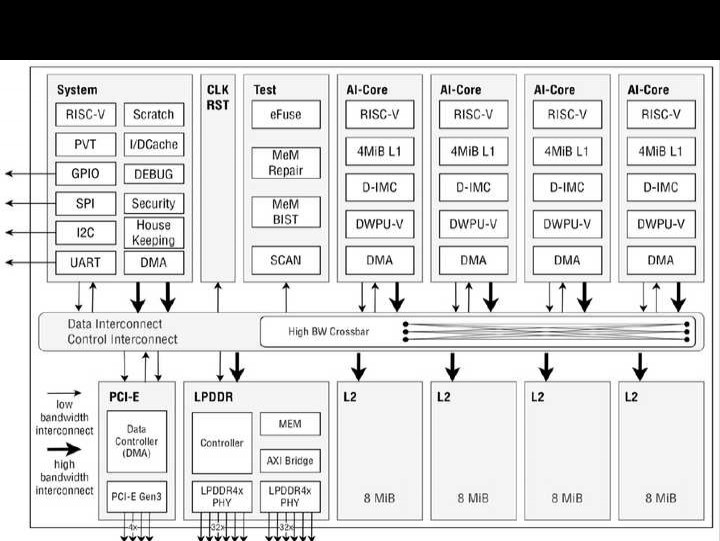
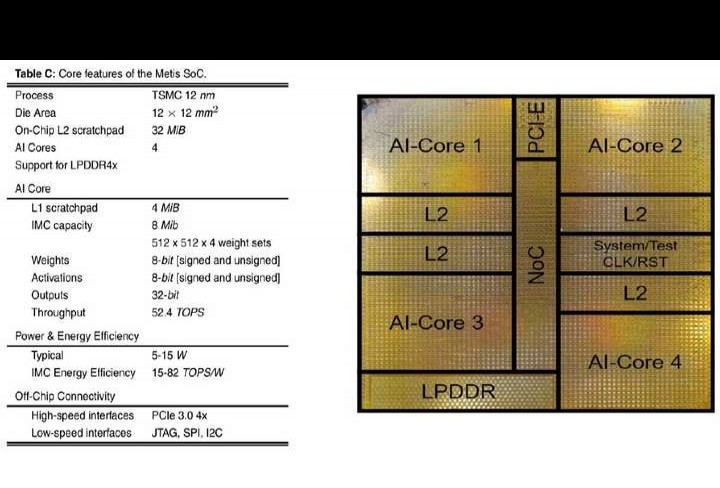
11.4 IBM NorthPole:一种采用12纳米芯片的神经网络推理架构。
名称:11.4 IBM NorthPole,神经网络推理架构,采用12nm芯片。
论文链接:https://ieeexplore.ieee.org/document/10454451。
IBM这一单位。
ISSCC 2024会议。
摘要:
算法、大数据以及用于训练大规模神经网络的更强劲的硬件处理器,这三者共同开启了深度神经网络(DNN)的时代。如今,在边缘、嵌入式和数据中心应用里,DNN被广泛用于神经推理,这就需要更节能的硬件处理器,并且要不断提升计算性能。为应对这一推理方面的挑战,我们开发出NorthPole架构,并实现了NorthPole芯片的实例化。
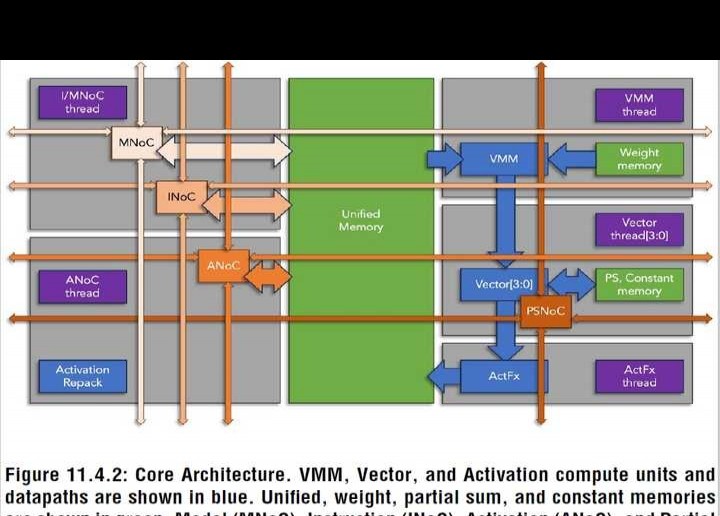

20.1 NVE:一种基于12位数字CIM、能效为23.2TOPS/W的3纳米神经引擎,用于智能设备上的高分辨率视觉质量增强。
名称:20.1 NVE。这是基于3nm、23.2TOPS/W、12b数字CIM的神经引擎,能提升智能设备高分辨率视觉质量。
论文链接:https://ieeexplore.ieee.org/document/10454482。
联发科:所属单位。
ISSCC 2024会议。
摘要:
在手机、电视、显示器等智能设备上,提升用户体验的关键在于提高视频质量。实际的硬件设计需在带宽、面积、能源预算的严格限制下,用最少资源实现高性能。深度学习算法在超分辨率(SR)、降噪(NR)等图像处理任务中被广泛应用,这更加凸显节能硬件解决方案的必要性。于是,将这些算法应用于实时和高分辨率场景成为新的关键需求。不过,达成这一目标存在若干挑战。
20.1.1所示:其一,高分辨率网络推理计算复杂、稀疏性低且精度要求高,这使其功耗大幅增加;其二,频繁与外部存储器进行高精度数据传输,会产生大量与带宽使用有关的功耗;其三,高效灵活的机制对支持多样网络结构和运营极为关键。

20.2A、基于28nm、能效达74.34TFLOPS/W的BF16异构CIM加速器:利用去噪相似性助力扩散模型。
20.2、28nm、74.34TFLOPS/W、BF16,基于CIM的异构加速器利用扩散模型的去噪相似性。
论文链接:https://ieeexplore.ieee.org/document/10454308。
清华大学这一单位。
ISSCC 2024会议。
摘要:
扩散模型(DM)是一类强大的生成模型,在图像合成上性能破纪录。由纯高斯随机变量生成的噪声图像,需经迭代的DM去噪才能保证生成质量。对DM而言,因激活分布改变和迭代时量化误差累积,将激活量化为整数(INT)会使图像质量下降。GPU(英伟达A100)用浮点(FP)DM迭代50次生成256×256的图像,需要2560毫秒和250瓦。相邻的两张去噪图像视觉效果相近,同一位置像素间差异极小。所以,对于相邻的两个DM,同一层(ΔIN)内大部分输入差异会一致地集中在较窄范围,这意味着大部分ΔIN可量化为INT数据。其余的ΔIN值相对较大,且在迭代DM中的分布有所不同。
为确保生成质量,完整的ΔIN张量被拆分为稠密INT张量(INT - ΔIN)和稀疏FP张量(FP - Δ)。内存计算(CIM)在INT乘法累加(MAC)方面有高吞吐量和能效优势,显示出其高效处理ΔIN的潜力。不过,现有的CIM芯片要以低功耗将设备上图像生成速度提升到几秒内,面临三个挑战。首先,传统CIM芯片采用位串行输入执行MAC,这会使运行时间变长。
近期的CIM芯片为处理更多输入位采用了额外的加法器树,这会使功耗增加85.4%、面积增大82.5%。并且,CIM芯片处理FP数据时无法达到INT数据那样的高速。其处理高精度尾数时需重复读/写,或者会遭遇漫长的对齐周期延迟。另外,以往的FP CIM不支持对存储的稀疏数据进行识别与利用,从而产生冗余计算。
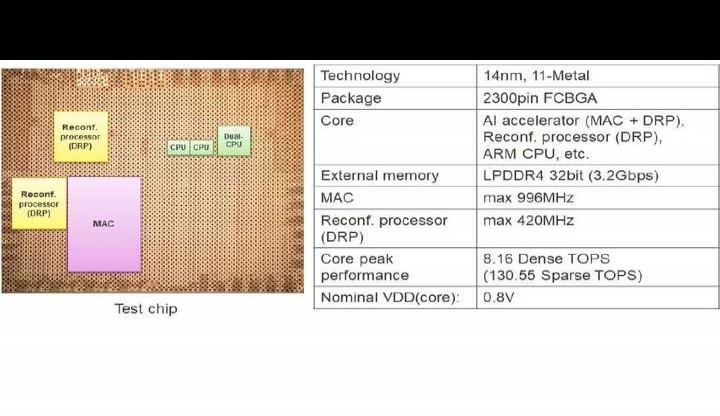
在14纳米异构嵌入式微处理器单元(MPU)中,有一款用于实时机器人应用的人工智能加速器。其在0.8伏电压下,能效达23.9万亿次运算每秒每瓦,性能为20.3万亿次运算每秒,且拥有16倍性能可加速剪枝技术,整体性能可达130万亿次运算每秒。
名称:20.3A、23.9TOPS/W(0.8V时)、130TOPS的AI加速器。它由14nm异构嵌入式MPU实现,可进行16倍性能加速修剪,能应用于实时机器人领域。
论文链接:https://ieeexplore.ieee.org/document/10454357。
单位:瑞萨(Renesas)。
ISSCC 2024会议。
摘要:
社会存在劳动力短缺等问题,人们愈发期待人类协作机器人能取得进步。这类机器人要实时同步处理先进的环境识别(以人工智能为主)、规划与控制(多为非人工智能算法)。
就当前的人工智能芯片来说,要达成这些目标颇具挑战性,原因在于:其一,需要峰值性能达到100TOPS级别的高性能人工智能加速器,在运用多摄像头系统进行大范围环境识别时尤其如此。不过,这种加速器功率超10W且需要大型风扇,无法集成到机器人设备里。其二,嵌入式CPU的性能不足,无法实时处理多个包含混合AI与非AI任务的机器人任务。为解决这些问题,我们提出了一种高能效的AI - MPU(微处理器单元),其包含:一是灵活的剪枝率控制(即灵活的N:M剪枝)技术,最多可将AI性能加速16倍;三是基于动态可重构处理器(DRP)、AI加速器(DRP - AI)和嵌入式CPU协作的多任务与实时机器人操作的异构架构。
20.4A:适用于边缘设备实时科学计算的28纳米物理计算单元,支持新兴的物理信息神经网络与有限元方法。
28纳米物理计算单元支持新兴物理信息神经网络与有限元方法,可在边缘设备进行实时科学计算(20.4)。
论文链接:https://ieeexplore.ieee.org/document/10454502。
西北大学这一单位。
ISSCC 2024会议。
摘要:
近年来,边缘设备的实时计算在人工智能等新兴应用的推动下需求急剧增长。近期,随着虚拟现实、物联网、机器人等实时应用不断发展,物理科学计算也备受关注。图20.4.1展示了物理实时计算的例子,像结构变形应用于逼真的VR/MR、机器人动态控制、增材制造中的温度监测以及实时泄漏气体追踪等。但边缘设备在数值科学计算方面的硬件支持较为薄弱,这影响了高精度、高分辨率物理计算的实时应用。图20.4.1中的VR/MR梁变形分析示例表明,由于收敛迭代次数太多,经典求解器无法达成实时延迟目标。近期虽设计出ASIC求解器用于通过有限差分法(FDM)求解泊松方程相关应用,不过在处理更复杂结构时存在困难。
科学界正在开发物理信息神经网络(PINN)或者物理信息机器学习(PIML)方案,目的是克服实时障碍,采用数据驱动的方式提高物理求解器的计算效率。从图20.4.1能够看出,和基于Nvidia Modulus的经典求解器相比,PINN方案能够加速1900 - 10000倍,并且精度损失低于1%。不过,要是PINN需要处理大量物理方程,那就得有高度多样化的数据流来支持各类PINN模型,这样一来,专用集成电路(ASIC)方案就不适用了。而且,对于特定的应用,在PINN和经典数值解之间要在速度和精度方面进行权衡。为了应对这些挑战,这项工作提出了一种统一物理计算单元(PhyCU)架构,这个架构对PINN和经典有限元方法(FEM)方案都提供支持。
PhyCU有以下亮点:其一,它提供了一种ASIC解决方案,能支持绝大多数具有可配置数据流的主要PINN模型进行推理;其二,PhyCU架构凭借共轭梯度迭代法(CG)原生支持经典FEM,这为使用相同硬件提供了高精度的替代方案;其三,开发出用于PINN和FEM计算的稀疏性与数据压缩技术,与GPU上的经典方案相比,其延迟降低了几个数量级,和之前的ASIC相比,节能19.5 - 35.9倍。

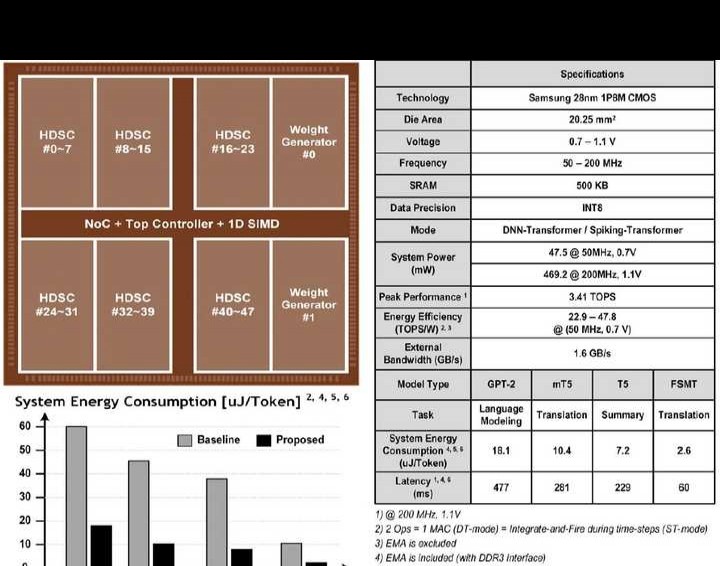
20.5 C - 变压器:一种针对大型语言模型、每标记能耗为2.6 - 18.1微焦的同构深度神经网络 - 变压器/脉冲 - 变压器处理器。它具备大小网络(Big - Little Network),并且有隐式权重生成功能。
名称:20.5 C - Transformer,这是一种2.6 - 18.1μJ/Token的处理器。它属于同质DNN - Transformer/Spiking - Transformer类型,具备Big - Little网络,还能进行大型语言模型的隐式权重生成。
论文链接:https://ieeexplore.ieee.org/document/10454330。
单位:韩国科学技术院。
ISSCC 2024会议。
摘要:
近期,像图20.5.1展示的那种基于Transformer的大语言模型(LLM)被广泛应用,甚至能预见到具备实时响应能力的设备端LLM系统的出现。不少Transformer处理器靠提升硬件利用率和降低功耗的方式来提高能效,不过它们的系统功耗和响应时间对移动设备而言仍不理想。由于GPT - 2等LLM参数众多(400 - 700M),其外部内存访问(EMA)占总功耗的68%。剪枝虽能增加稀疏性以突破EMA瓶颈,但仅可用于预测下一个单词这种简单任务(语言建模),在翻译、问答、摘要等高级任务中,无法实现高稀疏性(<~40%)。
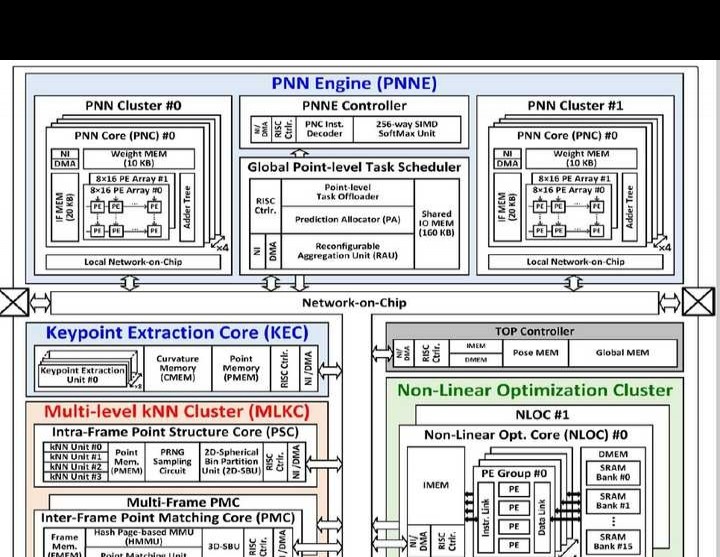
20.6 LSPU:一款完全集成的实时激光雷达同步定位与地图构建(LiDAR - SLAM)片上系统。它具备点神经网络分割功能,还有多级k近邻(kNN)加速功能。
名称:20.6 LSPU,这是完全集成的实时LiDAR - SLAM SoC,具备点神经网络分割与多级kNN加速功能。
论文链接:https://ieeexplore.ieee.org/document/10454374。
单位:蔚山国立科学技术学院。
ISSCC 2024会议。
摘要:
新兴的移动机器人若要实现自动驾驶,并与周边物体无缝交互,就需要同步定位与建图(SLAM)技术。以往基于RGB的视觉SLAM处理器存在诸多不足,像是视场范围有限、深度感知不够精准,而且极易受环境变化的干扰,所以无法应用于自动驾驶领域。
与之不同的是,LiDAR - SLAM算法能够凭借远程360°视点云提供精确的深度信息,从而构建出周围环境细致入微的情况,这也让它成为自主机器人极为关键的组成部分。图20.6.1展示了所提出的LiDAR - SLAM(LP - SLAM)系统完整的计算流程,涵盖3D空间感知、里程计和建图,其中每个阶段都包含多种算法。针对LiDAR的每一帧,点神经网络(PNN)会对3D点进行分割,并依据曲率图排序来提取关键点。之后,将这些关键点与之前的相匹配,以估算相对位姿,再通过Levenberg - Marquardt优化(LMO)构建出全局地图。LPSLAM主要有三个过程,分别为多级(帧内/帧间/多帧)k近邻(kNN)、PNN推理与关键点提取以及LMO。
然而,这些处理方式都不能达到移动计算平台上LiDAR(20fps)的实时速度要求。LP - SLAM极为复杂且需要海量内存,这使其难以在芯片上实现,并且面临诸多挑战。其一,用于生成点结构的大量帧内kNN操作成了计算瓶颈。而且,球形箱(SB)搜索虽然减少了用于关键点匹配的帧间/多帧kNN计算,但却因静态内存分配占用大量内存(约1.2MB/帧),从而产生大量外部带宽(约12GB/s)。其二,由于动态驾驶环境致使每个SB的工作负载不均衡,浪费了63%的PNN延迟。并且,在28.8k个点里,平均仅有7.9%被提取为关键点,92.1%被当作非关键点而被忽略,这造成排序阶段的冗余计算,阻碍了关键点提取的处理速度。其三,360°LiDAR的3D点会产生大量匹配点,与视觉SLAM相比,LMO所需的计算量要多出4.48至22.3倍。

20.7 NeuGPU:一种每次迭代耗能18.5毫焦的神经图形处理单元。它采用分段哈希架构,可用于即时建模和实时渲染。
名称:20.7 NeuGPU,这是一种神经图形处理单元,其18.5mJ/Iter,可用于分段哈希架构下的即时建模与实时渲染。
论文链接:https://ieeexplore.ieee.org/document/10454276。
单位:韩国科学技术院。
ISSCC 2024会议。
摘要:
元宇宙的兴起使3D建模和渲染技术的需求持续增加,这些技术能把现实世界的对象或场景融入移动设备的增强或虚拟世界里。近期,利用神经辐射场(NeRF)的3D建模和渲染逐渐流行起来,NeRF仅用2D图像来训练深度神经网络(DNN),就能创建逼真的3D模型,不需要用户手动设计,也无需高成本的3D扫描仪。以前的NeRF硬件只支持对不可见视图进行高帧率的3D渲染,没有即时建模功能,毕竟普通NeRF模型在单个NVIDIA V100 GPU上进行3D建模需要1 - 2天时间。
近期的NeRF模型借助哈希嵌入实现了相对快速的建模,可参考图20.7.1。不过,由于存在三个主要的硬件方面的难题,其建模时长仍超10分钟,渲染速度低于1fps,并且在资源受限的边缘GPU上功耗大于10W。
其一,哈希表(HT)参数众多(16个HT级别超过23MB),而边缘设备中典型的L2缓存(如Jetson TX2为512KB)连单个级别的HT都难以存储。而且,与哈希嵌入相关的不规则内存访问会提升缓存未命中率,造成大量片外内存访问,耗费90.0%的系统能量。
其二,用于哈希编码三线性插值的片上存储器访问会因存储体冲突而使吞吐量下降。虽然大量存储的SRAM(每层32个存储体)能够减轻冲突,但会消耗超过80%的插值功率以及产生面积开销。
其三,和普通NeRF加速不同,基于哈希的NeRF模型的低稀疏性特征(0 - 50%)使得多层感知器(MLP)加速时吞吐量和能源效率较低。
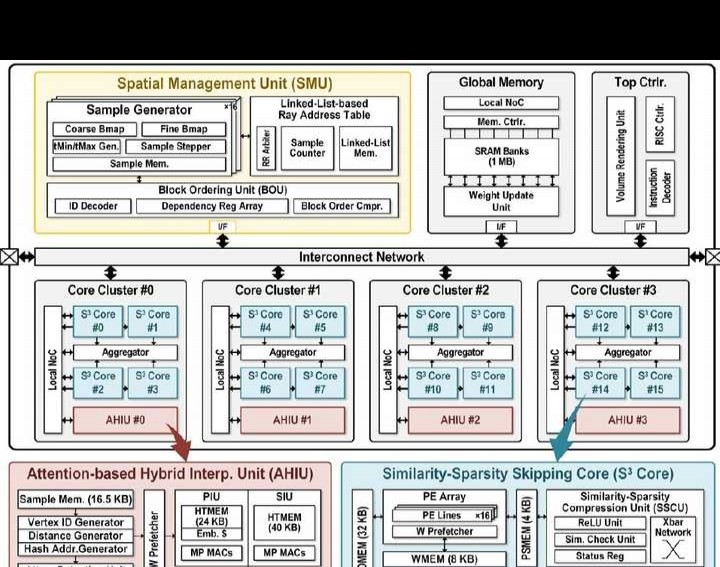
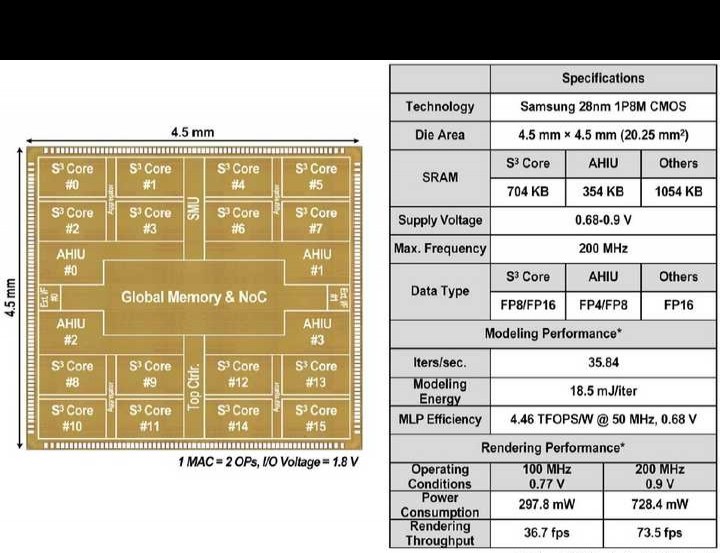
20.8 Space - Mate:一款用于移动空间计算的、功率为303.5mW的基于实时稀疏混合专家模型的NeRF - SLAM处理器
名称:20.8 Space - Mate,这是303.5mW的NeRF - SLAM处理器,可实时稀疏专家混合,用于移动空间计算。
论文链接:https://ieeexplore.ieee.org/document/10454487。
单位:韩国科学技术院。
ISSCC 2024会议。
摘要:
近年来,空间计算在移动设备(如自主机器人、增强现实眼镜等)中日益流行。它借助精确的用户位置,以及通过同步定位与地图(SLAM)算法获取的周围环境3D几何信息,达成网络物理交互。以往的SLAM处理器虽加速了建图与跟踪,但其支持的点特征很少(少于5000个),还需要额外进行后处理(体积融合)才能得到密集的3D地图。
大型(大于60MB)的高分辨率(小于4厘米体素)密集3D地图,其颜色/距离值以体素形式存储,这使得在内存有限的移动设备上进行实时的SLAM处理无法实现。基于神经辐射场(NeRF)的密集SLAM系统,它把低分辨率(20厘米)3D嵌入与用于颜色/距离解码的多层感知器相结合,达成了小内存占用(小于1MB)的3D地图表示(MLP)。不过,密集的MLP计算(在30fps时约为13TFLOPs)需要高端GPU,这对移动设备来说并不合适。
本文提出一种基于稀疏混合专家(SMoE)的NeRF - SLAM系统。该系统在每层动态使用小部分MLP参数(即专家),达成紧凑计算(计算量低至原来的1/6.9)和小内存占用(内存大小为原来的1/67.2),并且在副本数据集中,其误差比传统密集SLAM低2.3倍。
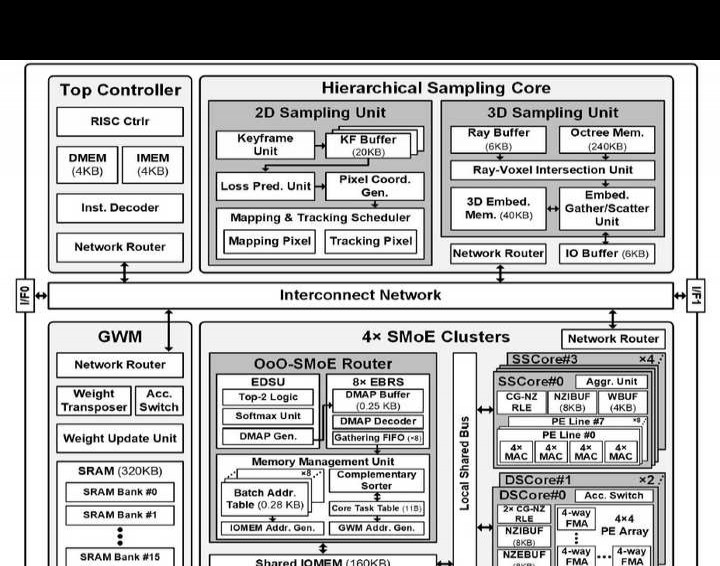
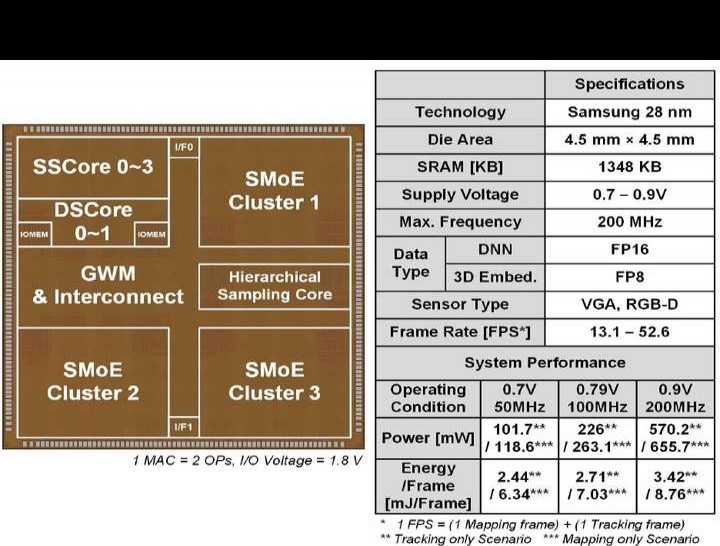
ISSCC会议上,中国高校与企业正迅速崛起。