抛开剂量谈毒性是耍流氓,不谈具体场景就说哪个方向更好,同样是耍流氓。
预训练(Per - Training)和微调(Fine - Tuning)都非常重要,它们是大型语言模型(LLM)训练不同阶段所需的技术。二者并无高低优劣,只是适用场景有别,并且要考虑具体项目需求与自身条件是否匹配。
当下,大模型正处于风口浪尖,吸引众多高手纷纷涉足。相关岗位招聘时,对候选人学历要求起码是硕士(本科基本没机会,HR看一眼就否决),求职者大多得是985/211毕业或者有大厂经验,还得做过NLP业务。
岗位大概有三个类型:字节等企业的大模型应用,各类研究院实验室的研究工作,百川那样提供解决方案的工作。当前企业多分布于北京和上海,想做研究选北京好,若做应用则两地都可考虑。
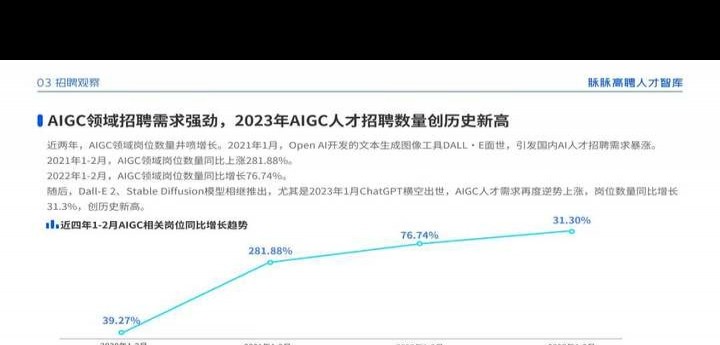
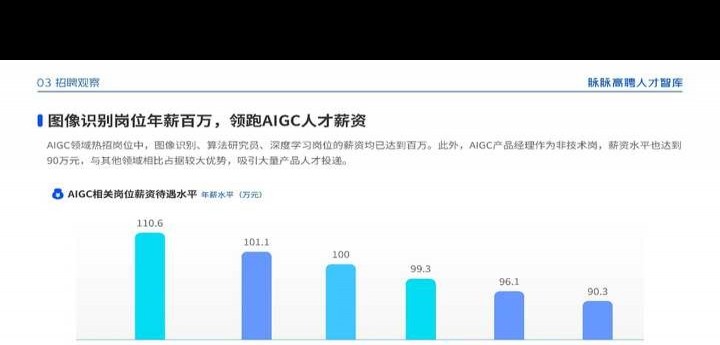
脉脉公布,2023年其相关领域人才招聘数量和岗位年薪均大幅领先,平均年薪百万有望,2024年这一趋势或将继续上升。

模型类人才招聘仍困难,非工资问题,而是有能力者太少。
有猎头透露小道消息,现在这类岗位特别缺人,薪资能涨30%到50%。所以很多原本不懂AI的程序员开始往大模型方向转,毕竟没人不想多赚钱。新兴行业要想进入就得趁早。但正因为是新行业,求职者在选岗位时更容易掉入陷阱。
有个偏算法研究、不直接涉及业务的部门,主要开展模型预训练工作。这个部门通常不大幅改动模型结构,而是将重点置于分布式训练。数据对模型的影响十分关键。在下游业务部门里,做SFT(监督微调)更多是优化prompt,促使业务场景与大语言模型(LLM)更好结合,让产品服务更优质。
提问者所说的这两个方向均在模型训练的范围内。当下国内AI行业处于野蛮生长时期,不少打着模型训练旗号的岗位,进去后才发现是做基础工作,也就是前三个步骤那些又苦又累的活儿。评论区的高手也指出,国内一些企业对数据组、模型组、预训练、SFT对齐等岗位采取隔离式管理,根本不存在偷师或者从基础岗位学起的可能。一旦入行就处在远离核心的岗位,这对职业规划会产生负面影响。
跟HR交谈时,务必清楚了解岗位具体工作内容,若发现实际与承诺不符,要及时质疑。
对LMM而言,资源就是那个关键的1,缺了它,再多也是0。要是没有好资源,就只能做下游任务。当非大厂让你做从0开始的大模型工作时,务必多个心眼,问清公司能给项目提供哪些资源,别糊里糊涂沦为做数据的工具人,毁了简历。
程序员面临裁员,AI模型类人才却供不应求。有时候,改变命运的不是努力,而是抉择。
我是网络老用户,刚刷到网络推出的程序员的AI大模型进阶之旅免费公开课,推荐给大家。这课里大模型发展历程、训练方法,还有用Fine - tuning训练自己模型等内容很干货,适合有程序员基础但不懂AI模型的朋友。参加课程还送Ai大模型资料包,新手不用到处找资料了,特别方便。
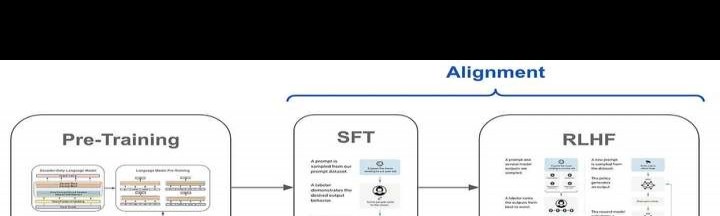
这里先分享两张思维导图,由Cameron R. Wolfe先生整理。这两张图可助大家迅速了解这两项工作的先后顺序与各自内容。
简单来讲,预训练在先,适用范围广。微调基于预训练,会局限于某个专业领域,任务也更具专业性。
在Fine - Tuning里,SFT(监督微调)和RLHF(人类反馈强化学习)是近年来较受关注的训练方式,它们也常被提及于模型训练中的对齐(Alignment)方面。这里就不再对RLHF进行展开阐述了。
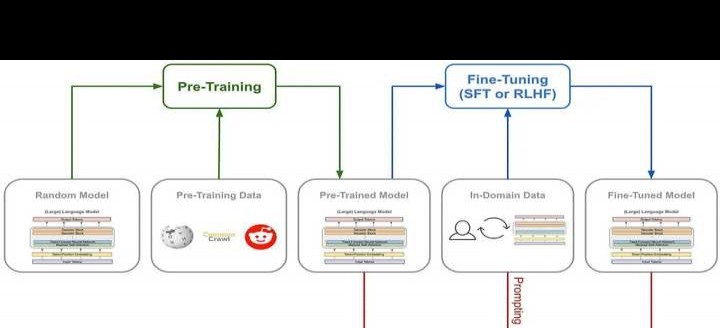
这里再分享一张Per - Training与Fine - Tuning具体特质的概括及对比情况。

预训练是大型语言模型(LLM)的基础。它从海量数据集中获取广泛的语言理解能力,让模型能针对不同主题生成连贯回应。简单来讲,这就像是教人工智能认字识词,不过在此过程中,它也可能答非所问,甚至胡言乱语。
预训练不但要有海量的语言理解,还需多种数据集来训练以及开发通用知识库,这样才能更好推动迁移学习,所以其初始计算成本较高。
预训练模型还有一大特征,即具备成本效益与灵活性。它能用新数据实现可扩展的改进和持续预训练,常为各类NLP任务确立基准。
微调是针对特定任务的,能提升模型在特定应用程序中的性能,通常让模型在小专业数据集高效学习。
它有诸多优势,像任务专业化、训练时间短、数据和资源利用效率高,这对利基应用程序与持续改进很有益。而且因其专业性,在医疗保健、金融等高风险领域允许微调来提升精确性。
预训练是横向的广度拓展,微调是纵向的深度挖掘。预训练如同厚积薄发的长期学习,微调可给特定业务需求快速精准的方案。
分析完这两大方向的差异后,接着谈谈它们的实际应用。
微调通常是在规模较小且带有特定任务标记的数据集中,对预训练模型做进一步训练。要是没有预训练这个基础,就无法进行微调,模型也就不能更精准地完成各类实际工作。例如翻译软件,未经微调的去翻译文学作品,会有很浓的机翻感,难以达到信达雅的要求。
预训练目前应用于普通翻译、内容审核等精度要求不太高的服务。而微调被用于细分市场中更专业(如医学、法律领域)且个性化的任务。
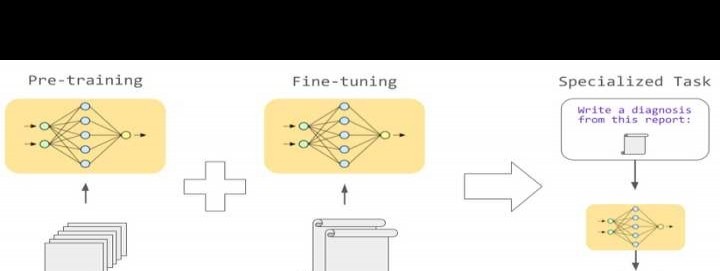
上面的图简洁明了地说明了Per - Training(预训练)和Fine - Tuning(微调)各自处理的数据类型,以及二者如何组合运用。把通用数据交给预训练模型学习,有了广泛的语言理解能力后,再让微调模型处理专业医学数据,最终实现理解医学专业词汇、解读医疗报告的目的。
再举几个例子如下:
在金融领域,公司也许会用预训练模型做一般性任务,像市场新闻情绪分析。不过,在审查合同是否符合财务法规、理解行业术语和分析特定报告时,就得用微调后的定制模型了。这种针对性调整能给出更精准的风险评估与投资建议。
销售时,预训练模型能应对常见客户查询,而微调后的定制模型可依据过往购买数据推荐产品、预测消费趋势,这还可用于定制营销策略与库存管理。
说了这么多,想必大家已明白预训练和微调在实际应用中的区别了。下面是干货时间:
从企业规模和相关业务性质出发,我们也能反推该公司可能更侧重哪个方向。
像Open AI、微软Copilot、谷歌Gemini、百度文心一言等,大公司往往有不同的人工智能需求,或许会在预训练上投入大笔资金(烧钱预警)来构建多功能模型。而专注于细分市场的初创公司,会更多地着力于利用微调,提高已有预训练模型的成本效益。
当然,对企业来说,真正有价值的常常是依据特定行业需求、客户互动和专业数据定制的模型。微调对模型适应特定业务或行业极为关键,它提供了能让AI服务快速推向市场的方案,促使从人工智障迈向人工智能。
总体而言,实力强、资金足的大厂提供的预训练岗位offer含金量往往更高,其岗位细分较完善,可避免成为洗数据的苦力。至于微调岗位是否靠谱,更多取决于项目能否提供完善的预训练模型与特定数据。
都提示到这种程度了,大家自会判断该如何选择。
人工智能持续发展,预训练和微调会逐渐被各行业所需,岗位需求很可能进一步增多。率先涉足人工智能领域的企业,在未来竞争中脱颖而出的可能性会大大提高。而且有AI大模型助力,还能推动创新,达成更高的运营效率。
那么,那些现在仍对AI模型持观望态度的程序员或者想入行的人,现在着手了解学习也不迟。网络在国内是顶尖的知识付费与分享平台,其邀请嘉宾分享的内容质量很有保障。免费课程已放在这儿了,免费课0元购,绝对超值,不会让你吃亏。