评价:这是标题党。
我来介绍个自己写的小工具,它与fastapi搭配使用超好用。
采用fastapi + pydantic - resolve + typescript来做前后端项目,根据项目实际体验,开发效率较普通写法能提高3到5倍,可维护性也非常强,项目周期越长,这种优势就越显著。
它以继承思想达成业务模型数据的复用与扩展,通过dataloader优雅地批量查询数据,借助post方法在每个对象的context里调整数据,以声明式、非侵入的方式实现数据装配。
先谈一谈fastapi在架构方面的一大便利之处,接着讲讲面向ER模型与pydantic - resolve是怎样高效进行数据组合的。
选择fastapi主要是看中其开箱即用的异步功能和对pydantic的支持。
重点来说说pydantic,它可是让开发体验大幅提升的大功臣。
fastapi通过pydantic与openapi - ts,达成了typescript sdk的自动生成。
生成的types能确保后端schema变动时,前端同步后马上察觉问题。以前前后端API整合最令人头疼,需求变更时会愈发耗时耗力,而有了typescript助力后,一切就变得清晰明了了。
此外,还可通过配置,利用tag对method进行分组,以解决api数量增多后的管理问题。
真正实现前后端一体化的开发体验。
但仅有这些还不能让开发体验大幅提升,还缺一样东西:面向ER模型的数据组合。
面向业务编程,复杂度为业务本质与代码实现复杂度之和。
ERD是面向业务的一种描述。若最终代码的具体实现(从形式上看)能尽量贴合ER模型,就能将业务变更与代码变更的差异减到最小。
日常开发时,数据上游若过早消除业务模型关系,下游就会对业务模型产生困惑。
这一过程包含三个部分。
完整提供ERD描述。
2. 对于不同业务,要从ERD里选子集,这时得确定入口数据(根数据)。
依据具体业务细节,调整该子集内的数据。
我们平常开发时,习惯过度依赖ORM/SQL(以下简称为ORM)这一种方式来描述ERD。实际上,ORM只是构建关系(relationship)的一种手段,并非全部。就像手里拿着锤子,就总想用锤子解决问题一样,仅使用ORM这一单一手段很容易陷入这种局限。
ORM很不错,但它在处理关联数据时存在着一些天然的限制。例如,不能进行跨库关联;层级较深的relationship查询时要留意查询性能的优化;逻辑复杂的relationship在书写与维护上不太方便;若将查询和业务处理都写在query里,代码的维护成本就会比较高,等等。
理想中的ERD不应有这些约束,要简单直接。Entity间建立关联的方式可以是join表、ORM关系,也可以是某种RPC调用,甚至是代码中的配置项。并且,两个Entity间应允许多种关系同时存在。
ER模型所描述的数据关系是可以存在的,是否关联则由具体业务场景确定。
关联为抽象描述,其具体实现可有多种方式。
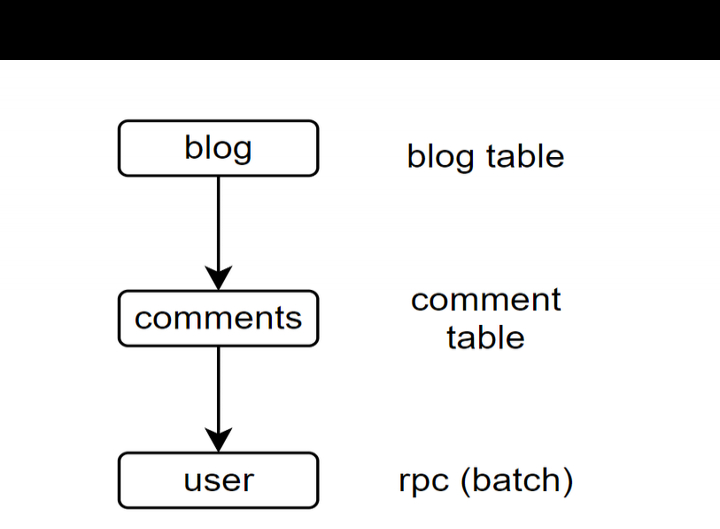
例如这三级资源之间的关联。
blogs和comments存储于数据库,二者借助ORM relationship获取blogs以及与每个blog相关联的comments。
comment的user信息经由user_ids从某个RPC批量获取user(例如部分信息需通过auth系统统一获取)。
一般来说,如果在普通情形下无法直接从orm关联获取user,那在获取blog和comments信息后,就得写两个循环,获取所有user_ids,然后发起请求,再逐个手动组装回去。这样做往往很冗长、效率低,要是层级再多一些,光那些for循环就会显得很啰嗦。
借助pydantic,我们能够直接描述这三层数据间的关系。假设外部rpc可通过某种dataloader加载,这样我们就无需编写和维护循环了,只需重点关注每层数据的内部状况就行。
如下代码片段描述了若干个Entity及其关联方式。
Blog(博客)、Comment(评论)、User(用户)为三个实体,UserLoader(用户加载器)是Comment与User之间的关系。
这种描述法先给出期望的数据结构,再用resolve方法提供真实数据。
pydantic - resolve将依据这些信息自动获取数据。
pydantic - resolve允许你依据期望的ERD(同时结合现有的数据模型)先描述出数据结构,之后再从各个数据源将数据组装起来。初始数据好比葡萄的枝干,而resolve节点能够在节点处计算出一粒粒葡萄(或者一串新葡萄)。
概念上或许与graphql有相似之处,不过用法不一样,graphql是从顶层出发,逐层执行方法来填充数据的。
而pydantic - resolve是从现有的数据对象着手,依据resolve_field和post_field方法,针对目标字段开展数据获取或者数据处理工作。
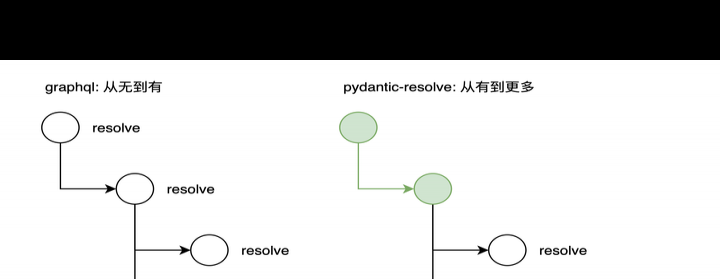
pydantic - resolve递归遍历结束后,每个node都有一个post method生命周期,可用于处理获取到的数据。这里面能做很多事情,很多在前端获取数据后处理起来棘手的事,在这儿都能轻松解决。
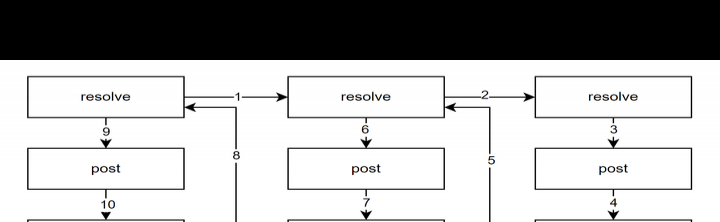
先做个小结。fastapi与pydantic - resolve实现了面向ERD编程,不再受ORM约束,使得数据拼接更加自由(不过自由度越大,对设计的要求也就越高)。
这也是我现在玩起来感觉超爽的一套玩法。
这里附上两个可本地执行的demo repo。
对于ER模型组合数据而言,ER图在产品和开发沟通中处于核心地位,非常重要。Entity(实体)间的relationship(关系)有众多规则,部分能在数据库层面处理,但也有些超出其能力范围,所以dataloder是一种更为通用的连接工具。
顺便说下dataloader的作用。例如我有一些blog_ids,需要查找与之关联的comments对象时,使用dataloader就可以先一次性收集好blog_ids,接着发送一个批次查询,然后它会在内部自动把查询结果分配回对应的comment。
这段代码构成了一个组合。该组合包含三个要素,即源实体(source entity)、目标实体(target entity)以及关系(relationsihp),它们分别对应着博客(Blog)、评论(Comment)和评论加载器(CommentLoader)。
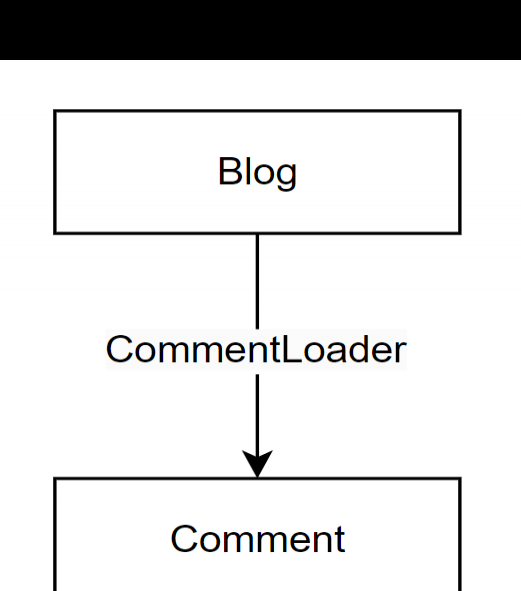
注意,不管输入数据是单个博客还是博客列表,CommentLoader的工作方式都是一样的。
具体可查看。
在dataloader内部,就由开发者自行实现了。它可以是本地数据库的where..in..查询,也可以是批量查询的rpc,还可以是某个本地配置文件。
顺便谈一谈dataloader,它的流行是伴随着graphql而产生的。不过在我眼中,dataloader在graphql里的使用方法有点浪费资源。具体的缘由等有空的时候再详细聊,就说一个最显著的问题,在graphql里使用dataloader是无法设置额外的过滤条件的。
所以,在graphql里,dataloder只能承担通过id查询数据这种比较低级的工作。
但是,ERD的关系应当允许你依据不同的组合情况添加不同的过滤参数。
重要的事情再说一次:组合与业务不同时,可设置不同的过滤参数。
创建一个数据时,会经历如下几个阶段:
Resolver会进行预检查,若所用Loader未提供参数,就会抛出异常。
采用dataloader模式后,关联数据的定义与获取可通过即插即用的方式组合,十分方便(还易于维护)。
关于dataloader就先谈到这儿吧。
可复用组合由一些实体(Entity)和关系(relationship)构成固定组合,可供复用。例如有用户信息(user info)数据时,需要展示用户及其一些关联信息。
例如:UserInfoDisplay = 继承(UserInfo)再加上扩展(LastLogin,CurrentStatus)。
首先假设我们已经有能返回UserInfo的loader,即UserLoader了。
既然UserInfoDisplay继承自UserInfo,只要UserLoader能返回UserInfo数据,该数据就能被继承的子类用作初始化数据。
从代码角度看,只要简单地将UserInfo替换成UserInfoDisplay,user info信息就自动完成升级了。
在整个过程里,UserLoader无需改动,这种玩法有点多态的意味。
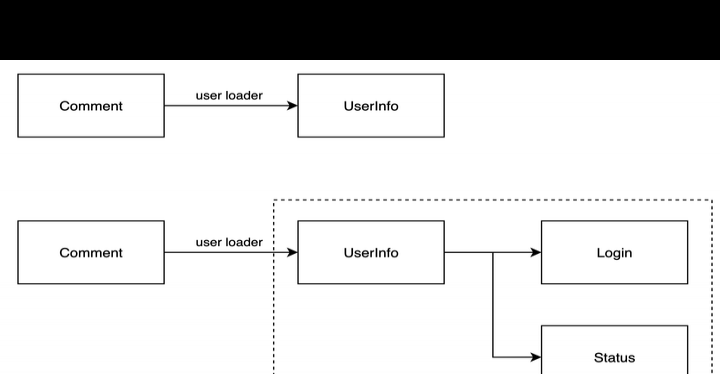
还有个小窍门,可在前端构建一个与UserInfoDisplay对应的组件,将其类型标记为UserInfoDisplay。这样一来,在任何需要展示用户信息的地方,只要凭借user_id从UserLoader获取数据,再返回标记为UserInfoDisplay的类型,就能够借助openapi - ts生成的sdk自动复用相应的组件了。
要是之后UserInfoDisplay内部有所调整的话,那只要修改与之对应的前端组件就可以了。
另外,从loader的性质来看,其batch请求数量由层级和深度触发。所以,不管UserInfoDisplay处于哪一层级,它的查询开销始终固定为三次(UserLoader、login、status),只是batch ids的数量有所不同罢了。
写到这儿,大家或许察觉到了,继承后子类的名称就是这个组合的ID。
GraphQL本身就天然蕴含着面向实体关系图(ERD)编程的思维,换个说法,按照ERD的思路去设计GraphQL的模式(schema)才是扩展性最优的方式。实际上,所谓的网络应用程序接口(web api),本质就是从多个或多层数据源整合数据的过程,这个过程既涉及数据获取,也包含数据调整。从这个角度看,GraphQL仅仅涉及数据获取环节,当获取到一串数据(就像一串葡萄那样)之后,若要依据具体业务逻辑进行裁剪、精修,往往就得重新遍历,层层循环,甚至要依靠很多临时变量辅助才能实现。
这个调整过程的代码往往不易阅读和维护,调整起来还很麻烦。
当然,也许有开发者会讲,自己平时不管这些事,这些流程都交给前端小哥处理了。
这种做法只是转嫁麻烦,并未将麻烦本身消除。
数据后处理有三类需求,假设数据结构为A -> B -> C三层。
第一种情况为,在B的resolve阶段完成之后,需依据获取的数据进行改动。例如计算C的数量、获取C中的最大值,也可按需求直接修改C的内容。
第二种情况是子孙节点需读取祖先节点的数据,像A的name字段,我得拿来和C中的C.name拼接在一起。
第三种情况为祖先节点能够收集子孙节点的数据。例如A可定义一个lastest_c,借助某种方式,越过B直接收集C字段,从而获取所有C节点中最晚的那一个。
另外,pydantic还有一个功能,即Field(exclude=True),它能让你在使用完一些临时字段后,在输出数据里将这些字段隐藏起来。
画图举例,resolve的过程为树的广度优先遍历。
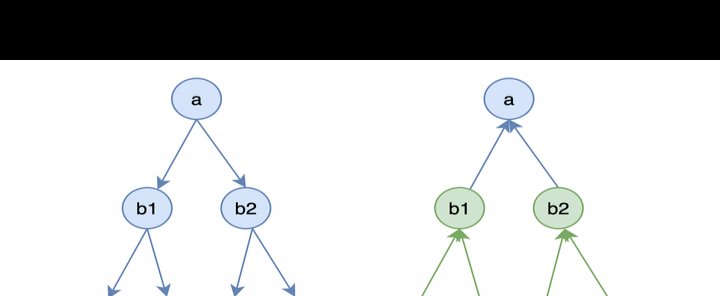
这一遍历过程遵循递归逻辑。在c1和c2遍历完成后,b1的post_method将被触发。对于b1而言,其所有子孙节点都已计算好,所以b1能按需处置。当全部b1、b2处理完后,a节点会进入post_method阶段,从而触发a中所定义的post逻辑。
换个角度看这棵树,post过程其实就是数据重新组织调整的过程。在开头阐述graphql缺点时就提到过:
在post方法里,层层循环的过程被隐藏于pydantic - resolve内部,开发者无需编写遍历逻辑了。
临时变量也置于节点内部,借助exclude=True在最终输出时隐藏(若不隐藏,可用于调试)。
一些负责跨节点数据收集与传送的临时变量,能通过expose和collect定义到节点内部,具体如下:
小结一下,借助post过程、expose以及collector这些方式,我们能基于获取到的数据灵活进行加工,这个过程不存在循环,也没有零散的临时变量。所有操作都是在schema里进行声明式描述,如此一来,整个计算过程就被可视化呈现出来了。
业务代码随业务变更易堆出难维护的代码,这种情况很常见。
业务变更存在一些一般规律,像最底层的数据结构通常不会轻易改变,不然整个项目都会受影响。
查询与变更的逻辑将发生改变,对一个Entity而言,变更逻辑绑定较紧,调整幅度不会太大。
新业务增加时,查询往往会产生各种新的组合。
所以长期项目一般都有这样的特点:会积累大量的查询语句,而且单个语句往往很复杂。要是查询中还包含数据转换等逻辑,那情况就更糟糕了。
分层视角下,解决办法为将查询与数据转换处理分离。
很多后端钟情于编写restful接口,这其实就是在进行分层实践。它能提供灵活且独立的数据查询结构,然后让前端或BFF自行拼接数据,如此便实现了部分查询功能的复用性。
数据面向ERD构建时也遵循这种思想。
Entity(实体)和Relationship(关系)(数据加载器)是一套可复用的数据结构与查询(查询层)。
通过继承与扩展得到的子类是面向具体业务的转换层(转换层)。
于是,业务代码的可维护性得到了改善。
dataloader是抽象接口,只要主要返回结构符合约定,其内部可任意实现。所以,若有性能问题,将dataloader内部实现拆分出来成为独立微服务也可行。这不过是从数据库查询转变成访问支持批量处理的RPC罢了,这些内部重构不会影响外部使用。
一个项目,度过早期摸索期十分关键。
早期需求不定,常修改,代码也得跟着被动调整。
组合模式能快速响应,它面向配置,调整就像重新拼搭积木,又与前端类型绑定,集成修改过程很平滑。
prototype框架的优势在于可快速组合、快速验证,通过迭代得到稳定的数据结构。
性能上,它仅是接口,内部实现可在后续重构时等价替换。
以ERD为导向构建数据,其优势在于速度快且与产品模型贴近。在功能修改与迭代时,既能轻松理解旧代码含义,又能便捷调整为新结构。
修改嵌套数据结构:遍历、调整节点并维护context变量。
使用pydantic - resolve能够省掉遍历相关的代码。
context变量可通过expose、parent等方式实现,不必定义众多临时变量,如此可避免变量维护时出现混乱状况。(具体可参考expose和parent的文档)